.
バッチプロセシングインタフェース¶
はじめに¶
すべてのアルゴリズム(モデルを含む)はバッチプロセスとして実行することができます.すなわち,それらは単一の入力のセットではなく,それらのいくつかを使用して実行でき,必要に応じて何度でもアルゴリズムを実行できます.大量のデータを処理する際には,ツールボックスからアルゴリズムを何回も起動する必要がないので,これは有用です.
アルゴリズムをバッチプロセスとして実行する場合ツールボックスの名前を右ボタンクリックして表示されるポップアップメニューで Execute as batch process を選択して下さい
Figure Processing 26:
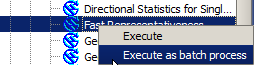
右クリックのバッチプロセッシング 
パラメータテーブル¶
バッチプロセスの実行は、アルゴリズムの単純な実行と類似しています。パラメータ値を定義しなければならないが、この場合は、各パラメータに単一の値を設定する必要はありません。値は次に示すようなテーブルを使って紹介しています。
Figure Processing 27:
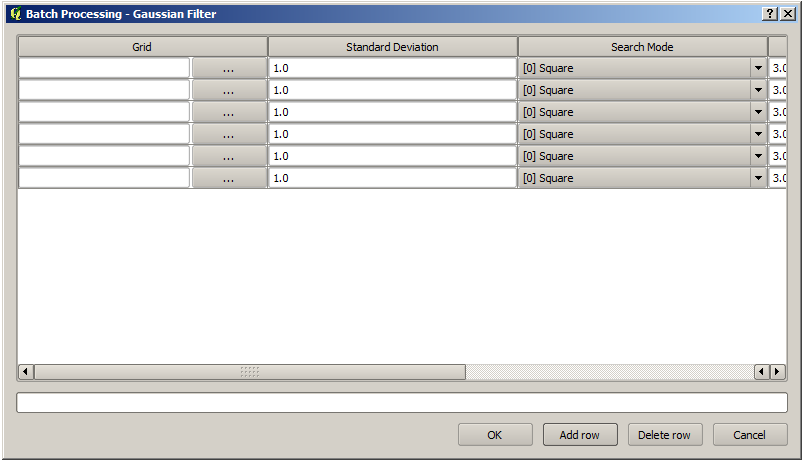
バッチプロセッシング
このテーブルの各行はアルゴリズム単一の実行を表し、各セルはパラメータの1つを含みます。これはツールボックスからアルゴリズムを実行する際に表示されるパラメータダイアログと類似しており、配列が異なっています。
デフォルトではテーブルhは2行のみ含んでいます。ウィンドウの下部にあるボタンを使って、行の追加や削除ができます。
テーブルのサイズが設定されると適切な値で埋められます.
パラメータテーブルの入力¶
たいていのパラメータで,その値を設定するのは些細なことです.値を直接入力するか,パラメータタイプに応じて,利用可能なオプションのリストから選択するだけです.
主な違いはレイヤやテーブルで代表されるパラメータ,および出力ファイルに対して見られます.入力レイヤとテーブルについて,アルゴリズムがバッチプロセスの一部として実行された時、入力データオブジェクトは, QGIS ですでに開かれたファイルのセットからでなくファイルから直接取得されます.その理由として,任意のアルゴリズムがすでに開かれたデータのないオブジェクトに対してバッチプロセスを実行して、アルゴリズムをツールボックスから実行できません.
データオブジェクトを入力するためのファイル名は直接入力により導入されるか,より簡便には、典型的にはファイル選択ダイアログのセルの右側に表示される  をクリックする。入力されたパラメータが一つのオブジェクトを意味し、いくつかのファイルが選択されると、それらの一つ一つが別々の列に投入され、必要であれば新たなものが加えられる。それが複数のものを示す場合、すべての選択されたファイルはセミコロン(;)で分割されて、一つのセルに加えられる.
をクリックする。入力されたパラメータが一つのオブジェクトを意味し、いくつかのファイルが選択されると、それらの一つ一つが別々の列に投入され、必要であれば新たなものが加えられる。それが複数のものを示す場合、すべての選択されたファイルはセミコロン(;)で分割されて、一つのセルに加えられる.
ツールボックスからアルゴリズムを実行する時と異なり、出力データオブジェクトは常にファイルとして保存され、一時的にそれを保存することは許可されていません。名称を直接入力するか、添付のボタンをクリックして表示されるファイル選択ダイアログを使用します。
いったんファイルを選択すると、新しいダイアログが同じ列(同じパラメータ)内の他のセルの自動補完を行うために表示されます。
Figure Processing 28:
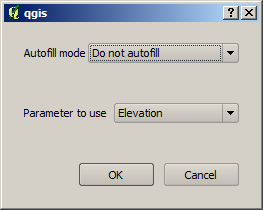
バッチプロセッシング保存
もしデフォルトの値 (‘自動補完しない’) が選ばれた場合は、パラメータテーブルから選択されたセルの中の選択されたファイル名が選ばれます。もし、その他のオプションが選ばれた場合は、以下の選択された全てのセルは定義された条件に基づいて自動的に入力されます。この方法は、テーブルを埋めるよりはるかに簡単で、バッチプロセスは最小の労力によって定義することが出来ます。
自動入力は、単に選択したファイルパスに相関的な番号を追加するか、同じ行で別のフィールドの値を追加して行うことができます。これは、入力されたものに応じて出力データオブジェクトを命名するのに特に役立ちます。
Figure Processing 29:
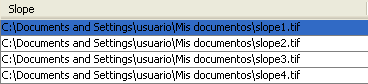
バッチプロセッシングのファイルパス