21. Fișă de răspunsuri¶
21.1. Results For Adăugarea Primului Dvs. Strat¶
21.1.1.  Pregătire¶
Pregătire¶
You should see a lot of lines, symbolizing roads. All these lines are in the vector layer that you just loaded to create a basic map.
21.2. Results For O privire de ansamblu asupra interfeței¶
21.2.1. Vedere Generală (Partea 1)¶
Consultați iarăși imaginea care prezintă aspectul interfeței și verificați dacă vă amintiți numele și funcțiile elementelor de pe ecran.
21.3. Results For Lucrul cu Datele Vectoriale¶
21.3.1. Shapefiles¶
There should be five layers on your map:
locații
- water
- buildings
- rivers and
- roads.
21.3.2. Databases¶
All the vector layers should be loaded into the map. It probably won’t look nice yet though (we’ll fix the ugly colors later).
21.4. Results For Symbologie¶
21.4.1. Culori¶
Verificați dacă puteți schimba culorile după dorință.
- It is enough to change only the water layer for now. An example is below, but may look different depending on the color you chose.

Note
If you want to work on only one layer at a time and don’t want the other layers to distract you, you can hide a layer by clicking in the check box next to its name in the Layers list. If the box is blank, then the layer is hidden.
21.4.2. Structura Simbolului¶
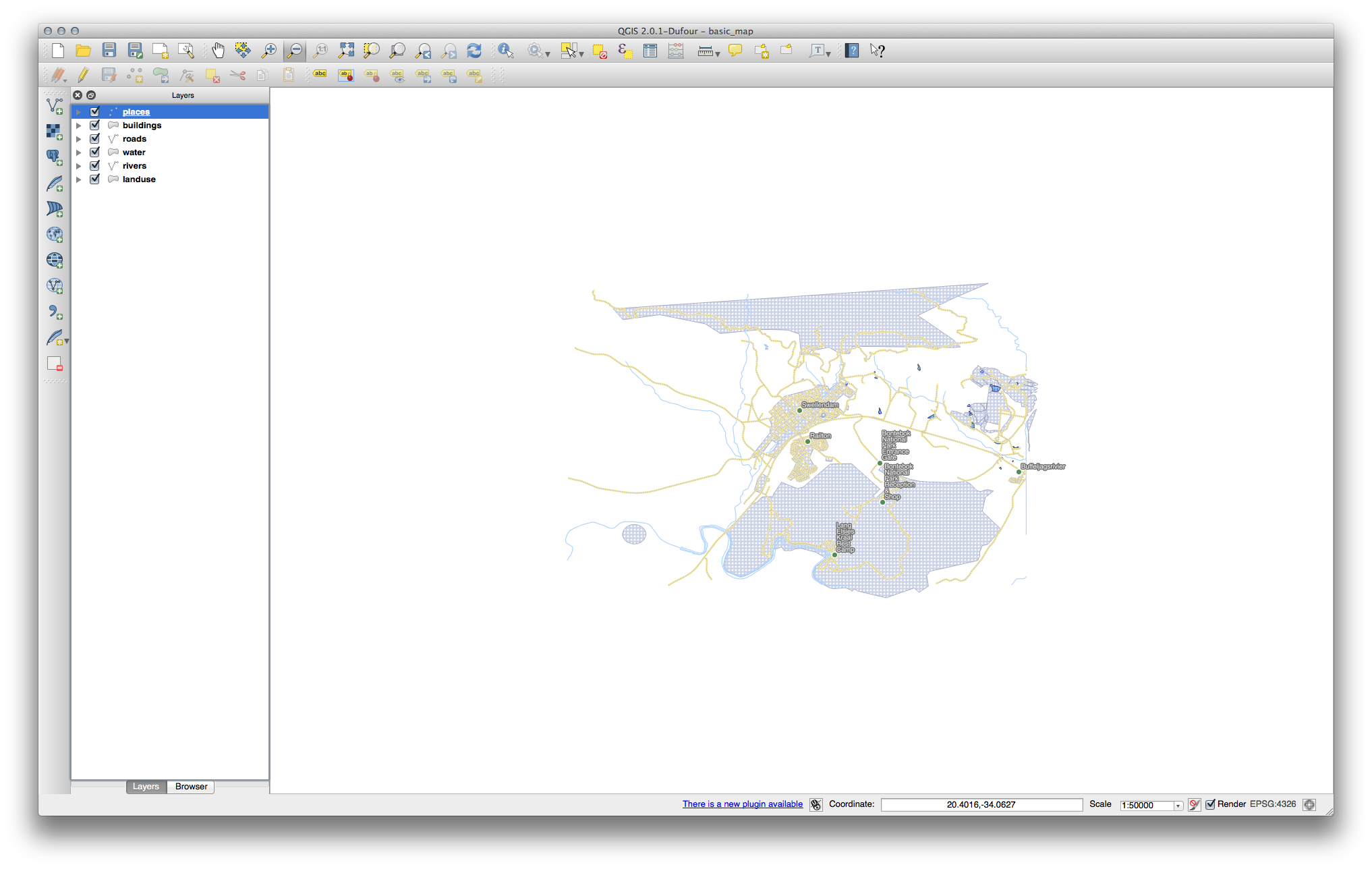
Harta ar trebui să arate așa:

Dacă sunteți la nivelul de Utilizator Începător, v-ați putea opri aici.
Utilizați metoda de mai sus pentru a schimba culorile și stilurile pentru toate straturile rămase.
Încercați să folosiți culori naturale pentru obiecte. De exemplu, un drum nu ar trebui să fie de culoare roșie sau albastră, dar poate fi de culoare gri sau neagră.
- Also feel free to experiment with different Fill Style and Border Style settings for the polygons.
21.4.3.  Straturile Simbolului¶
Straturile Simbolului¶
Personalizați-vă stratul de clădiri așa cum doriți, dar nu uitați că trebuie să fie ușor să distingeți diferitele straturi de pe hartă.
Iată un exemplu:

21.4.4. Nivelurile Simbolului¶
To make the required symbol, you need two symbol layers:
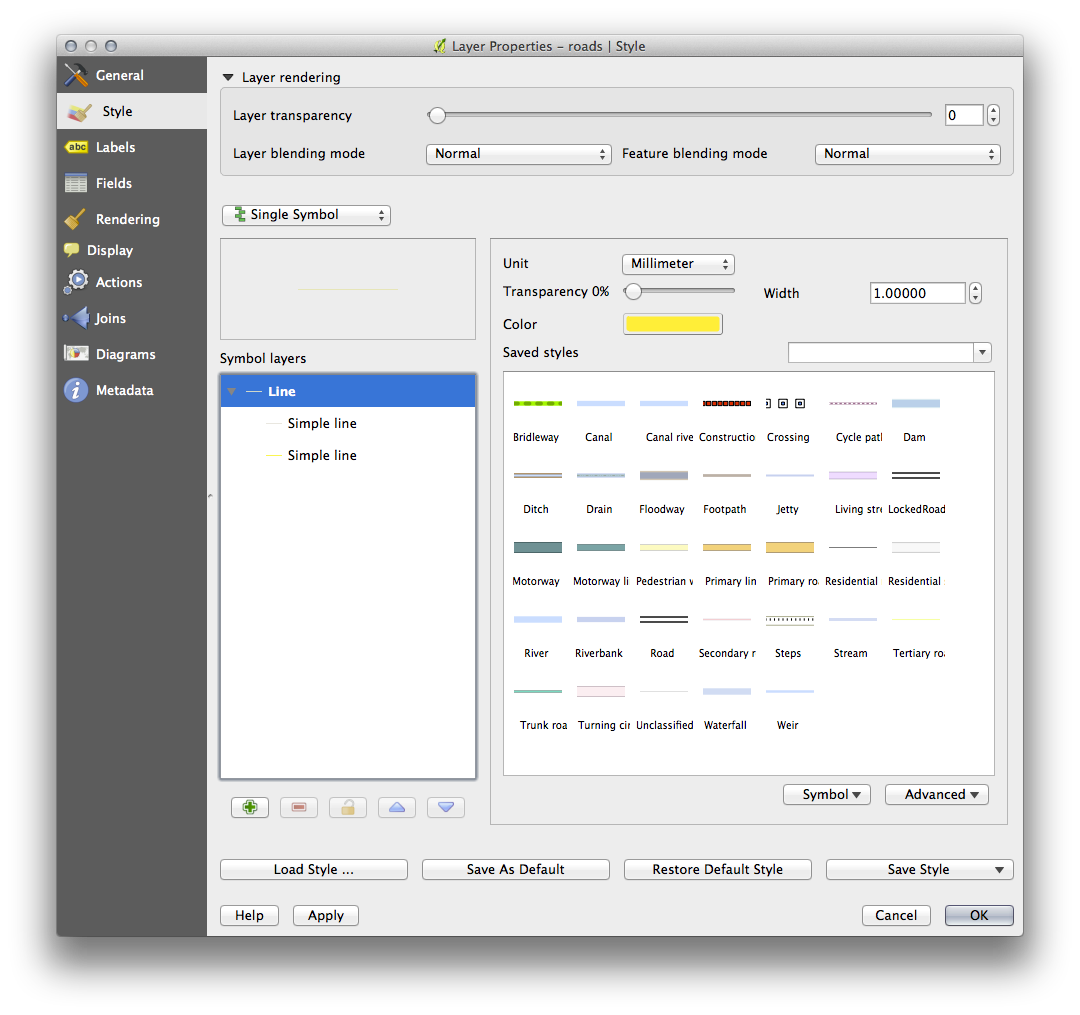
The lowest symbol layer is a broad, solid yellow line. On top of it there is a slightly thinner solid gray line.
If your symbol layers resemble the above but you’re not getting the result you want, check that your symbol levels look something like this:

Acum, harta ar trebui să arate în felul următor:

21.4.5.  Nivelurile Simbolului¶
Nivelurile Simbolului¶
Ajustați nivelurile simbolurilor la aceste valori:

Experimentați cu valori diferite, pentru a obține rezultate diferite.
Deschideți iarăși harta originală, înainte de a continua cu exercițiul următor.
21.5. Atributele Datelor Results For¶
21.5.1. Atributele Datelor¶
The NAME field is the most useful to show as labels. This is because all its values are unique for every object and are very unlikely to contain NULL values. If your data contains some NULL values, do not worry as long as most of your places have names.
21.6. Results For Instrumentul Etichetă¶
21.6.1. Personalizarea Etichetelor (Partea 1)¶
Harta ar trebui să prezinte acum punctele marcajelor și ale etichetelor decalate cu 2.0 mm: Stilul marcajelor și al etichetelor trebuie să permită observarea pe hartă a ambelor, cu claritate:

21.6.2. Personalizarea Etichetelor (Partea a 2-a)¶
O soluție posibilă o reprezintă acest produs final:
Pentru a ajunge la acest rezultat:
Utilizați o dimensiune a fontului de 10, o Distanță a etichetei de 1,5 mm, Lățimea simbolului and Înălțimea simbolului de 3.0 mm.
În plus, acest exemplu folosește opțiunea de Încadrare a etichetei după caracter:

Introduceți un spațiu în acest câmp și faceți clic pe Apliccare, pentru a obține același efect. În cazul nostru, unele dintre numele de locuri sunt foarte lungi, rezultând astfel nume cu linii multiple, ceea ce nu este foarte plăcut. ți putea găsi această setare, ca fiind mult mai adecvată pentru harta dvs.
21.6.3. Utilizarea Setărilor Definite cu ajutorul Datelor¶
Fiind încă în modul de editare, setați valorile FONT_SIZE după dorință. În exemplu se folosesc 16 pentru orașe, 14 pentru suburbii, 12 pentru comune și 10 pentru sate.
Amintiți-vă să salvați modificările și să ieșiți din modul de editare.
Întoarceți-vă la opțiunile de formatare ale Textului pentru stratul locații și selectați FONT_SIZE în Câmpul atribut al meniului de suprascriere a dimensiunii fontului:

Rezultatele, dacă se utilizează valorile de mai sus, ar trebui să fie următoarele:

21.7. Results For Clasificare¶
21.7.1. Rafinarea Clasificării¶
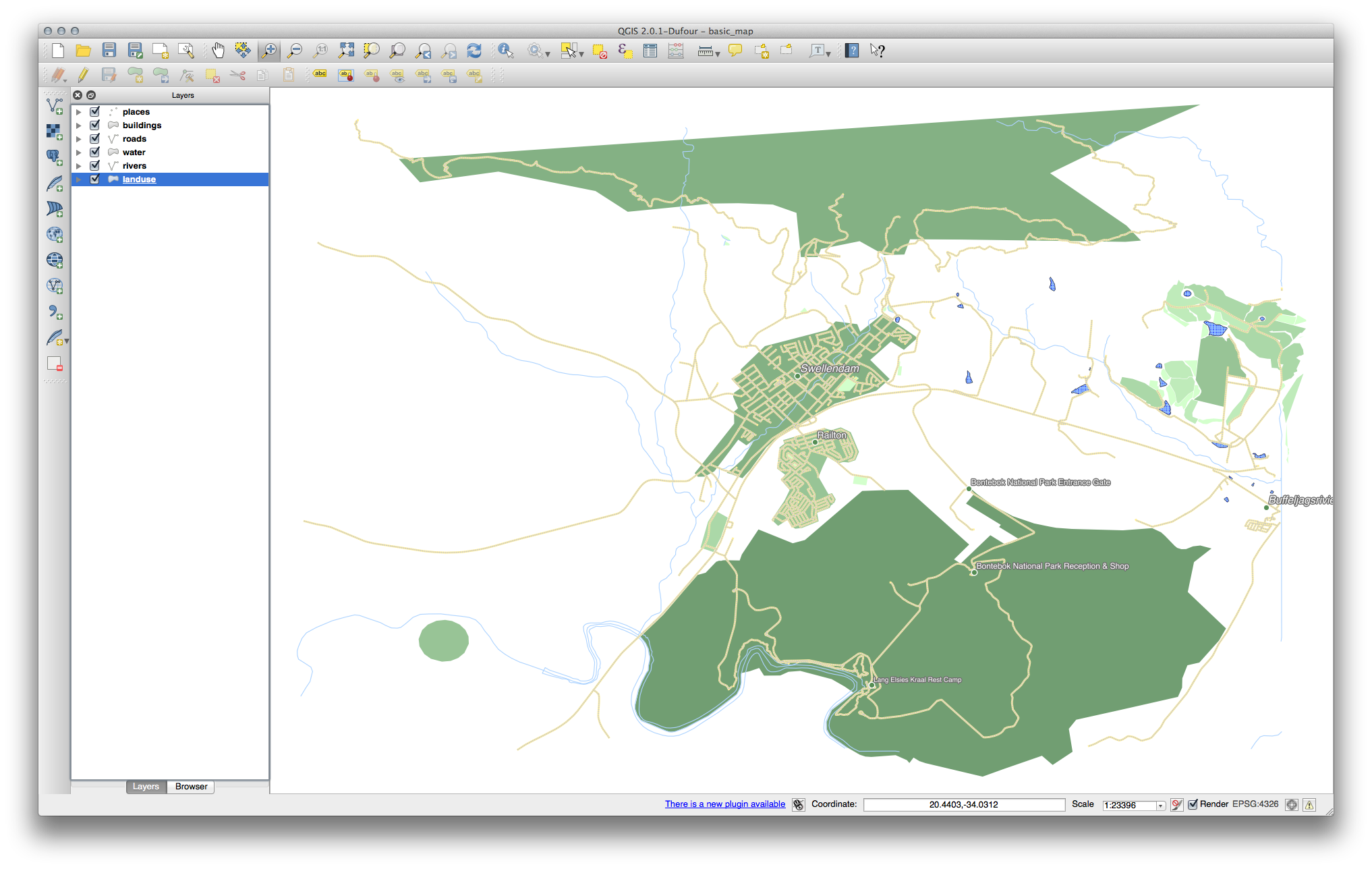
Folosiți aceeași metodă ca și în primul exercițiu al lecției, pentru a scăpa de frontiere:

Setările pe care le utilizați pot să nu fie similare, dar cu valorile pentru Clase = 6 și Mod = Intervale Naturale (Jenks) (și folosind aceleași culori, desigur), harta va arăta astfel:
21.8. Results For Crearea unui Nou Set de Date Vectoriale¶
21.8.1. Digitizare¶
Simbolistica nu contează, dar rezultatele ar trebui să arate mai mult sau mai puțin ca acesta:

21.8.2. Topologia: Adăugarea Instrumentului Inel¶
Forma exactă nu contează, dar ar trebui să fie obțineți o gaură în mijlocul entității dvs., ca aceasta:

Anulați editările dumneavoastră înainte de a continua exercițiul pentru instrumentul următor.
21.8.3. Topologia: Adăugarea Instrumentului Parte¶
Mai întâi selectați Bontebok National Park:
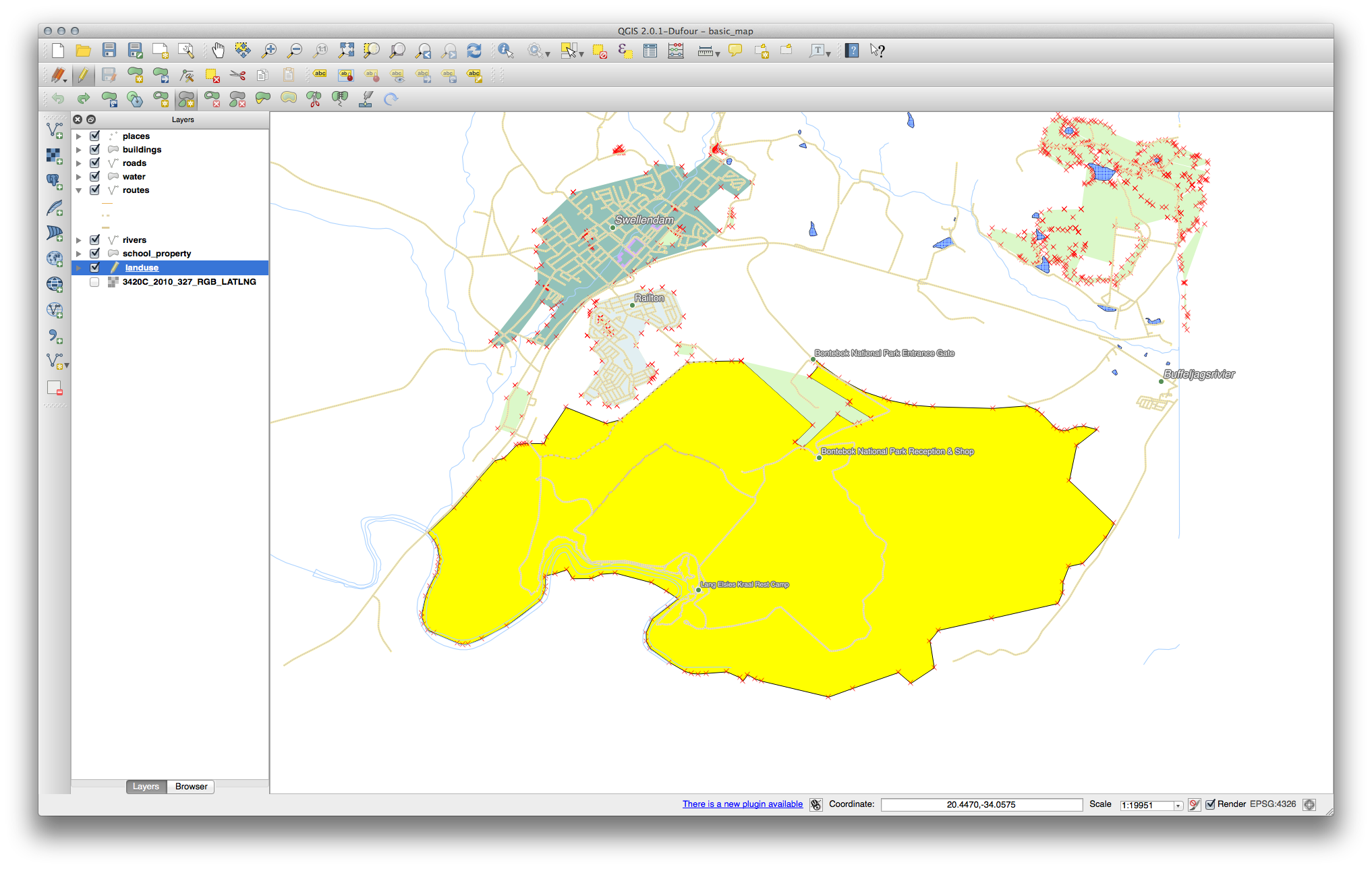
Acum, adăugați noua parte:

Anulați editările dumneavoastră înainte de a continua exercițiul pentru instrumentul următor.
21.8.4. Îmbinare Entități¶
Folosiți instrumentul de Îmbinare a Entităților Selectate, asigurându-vă că ați selectat mai întâi ambele poligoane pe care doriți să le îmbinați.
Utilizați entitatea cu OGC_FID-ul 1 ca sursă pentru atributele dvs. (clic pe intrările sale din dialog, apoi faceți clic pe butonul Preia atributele din entitatea selectată):
Note
- Dacă utilizați un set de date diferit, este foarte probabil ca
OGC_FID-ul original al poligonului dvs. să nu fie 1. E suficient să alegeți entitatea care are un OGC_FID.

Note
Folosind instrumentul de Îmbinare a Entităților Selectate,vom păstra geometriile distincte, dar le vom acorda aceleași atribute.
21.8.5. Formulare¶
Pentru TIP există, în mod evident, o cantitate limitată de tipuri de drumuri, iar dacă veți verifica tabelul de atribute pentru acest strat, veți vedea că acestea sunt predefinite.
Setați widget-ul la Valorile Hărții apoi faceți clic pe Încărcare Date din Strat.
Selectați drumurile din caseta cu derulare verticală a Etichetelor și autostrăzile pentru opțiunile Valoare și Descriere:

Faceți clic pe Ok de trei ori.
Dacă veți folosi instrumentul Identificare asupra unei străzi, în timp ce modul de editare este activ, dialogul ar trebui să arate astfel:

21.9. Results For Analiza Vectorială¶
21.9.1. Extract Your Layers from OSM Data¶
For the purpose of this exercise, the OSM layers which we are interested in are multipolygons and lines. The multipolygons layer contains the data we need in order to produce the houses, schools and restaurants layers. The lines layer contains the roads dataset.
The Query Builder is found in the layer properties:

Using the Query Builder against the multipolygons layer, create the following queries for the houses, schools, restaurants and residential layers:



Once you have entered each query, click OK. You’ll see that the map updates to show only the data you have selected. Since you need to use again the multipolygons data from the OSM dataset, at this point, you can use one of the following methods:
- Rename the filtered OSM layer and re-import the layer from osm_data.osm, OR
- Duplicate the filtered layer, rename the copy, clear the query and create your new query in the Query Builder.
Note
Although OSM’s building field has a house value, the coverage in your area - as in ours - may not be complete. In our test region, it is therefore more accurate to exclude all buildings which are defined as anything other than house. You may decide to simply include buildings which are defined as house and all other values that have not a clear meaning like yes.
To create the roads layer, build this query against OSM’s lines layer:

You should end up with a map which looks similar to the following:

21.9.2. Distanța față de Licee¶
Dialogul tamponului dvs. ar trebui să arate astfel:

The Buffer distance is 1000 meters (i.e., 1 kilometer).
The Segments to approximate value is set to 20. This is optional, but it’s recommended, because it makes the output buffers look smoother. Compare this:

Cu aceasta:

The first image shows the buffer with the Segments to approximate value set to 5 and the second shows the value set to 20. In our example, the difference is subtle, but you can see that the buffer’s edges are smoother with the higher value.
21.9.3. Distanța față de Restaurante¶
To create the new houses_restaurants_500m layer, we go through a two step process:
În primul rând, creați un tampon de 500 de metri în jurul restaurantelor și adăugați stratul la hartă:

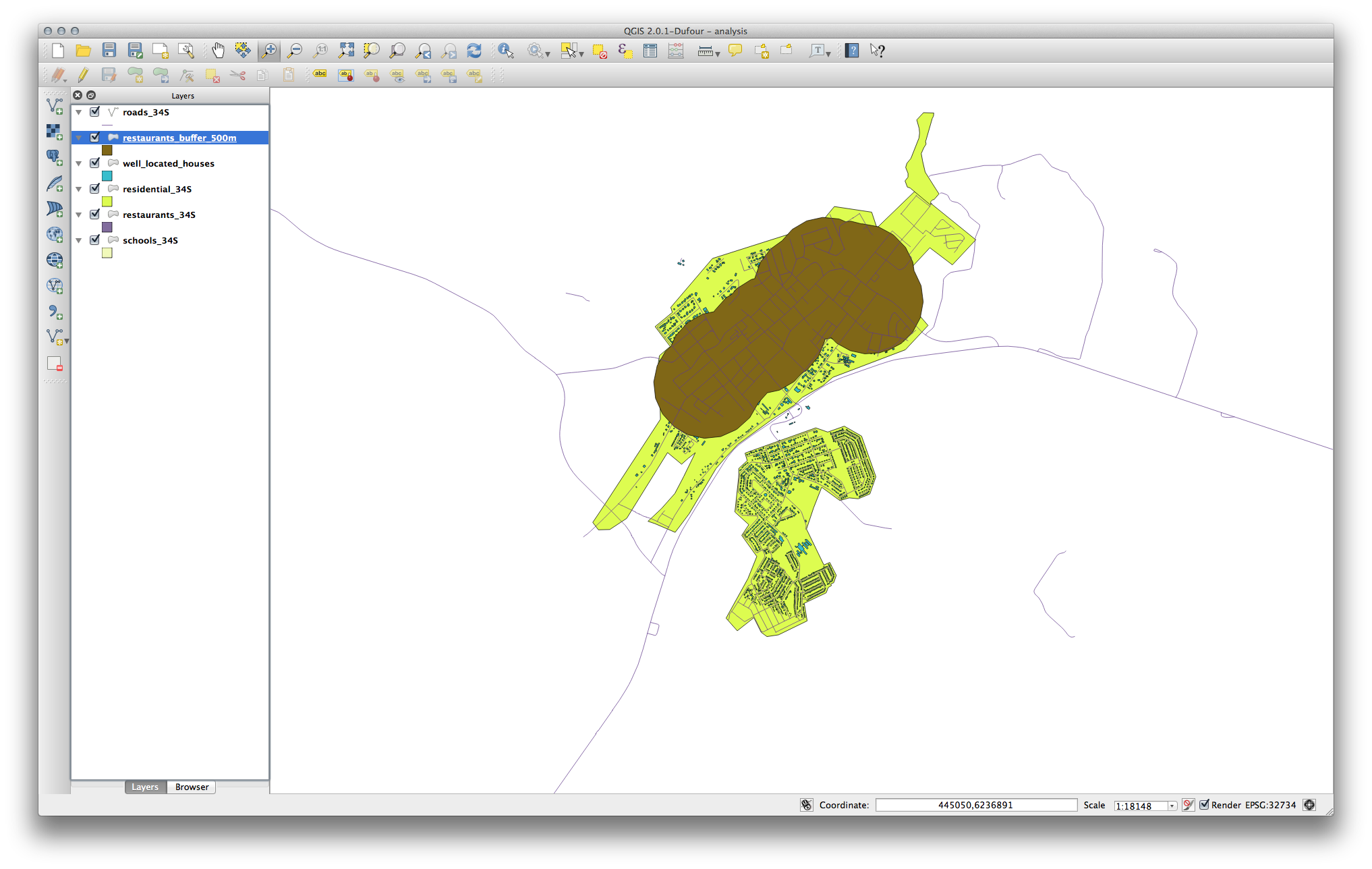
Next, select buildings within that buffer area:

Now save that selection to our new houses_restaurants_500m layer:

Harta dvs. ar trebui să arate acum numai acele clădiri care sunt la 50 m față de drum, la 1 km de o școală și la 500 m de un restaurant:

21.10. Results For Analiza Raster¶
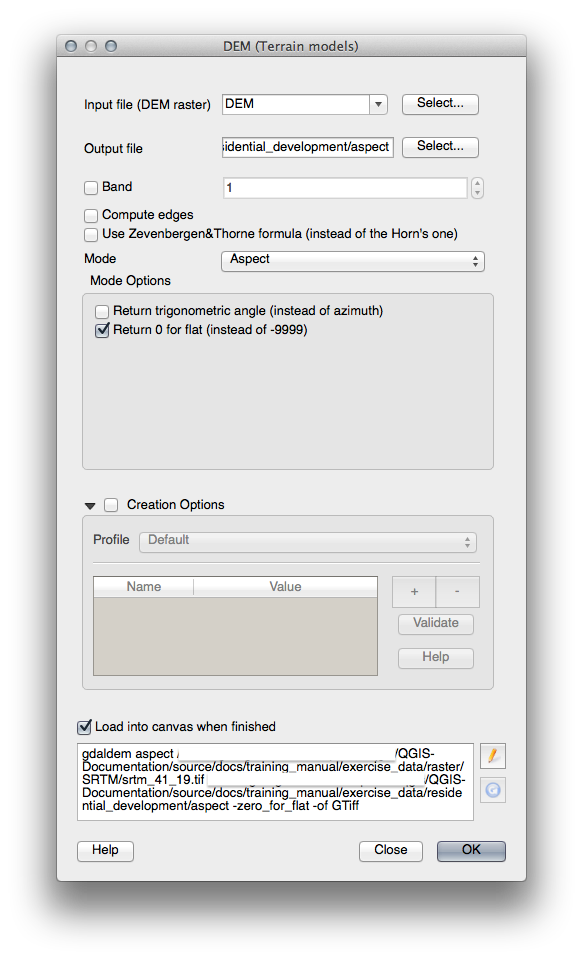

21.10.2. Calculează Panta (mai puțin de 2 sau de 5 grade)¶
Setați dialogul Calculatorului Raster în felul următor:
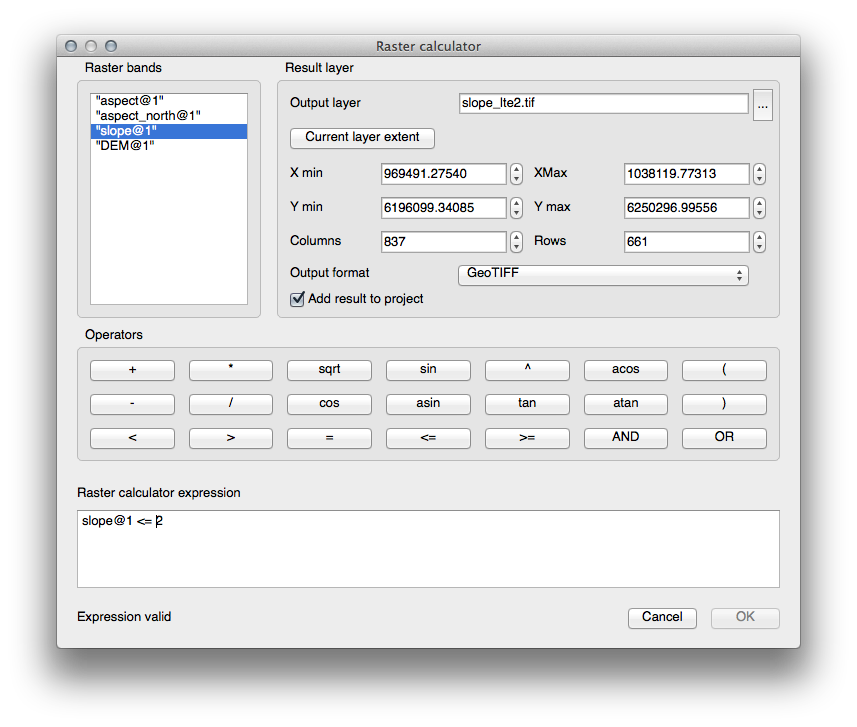
For the 5 degree version, replace the 2 in the expression and file name with 5.
Rezultatele dvs.:
2 grade:

5 grade:

21.11. Results For Completarea Analizei¶
21.11.1. Din Raster în Vector¶
- Open the Query Builder by right-clicking on the all_terrain layer in the Layers list, select the General tab.
Apoi construiți interogarea kbd:“suitable” = 1.
Clic pe OK pentru a filtra toate poligoanele în care această condiție nu este îndeplinită.
Atunci când sunt puse deasupra rasterului original, zonele trebuie să se suprapună perfect:

- You can save this layer by right-clicking on the all_terrain layer in the Layers list and choosing Save As..., then continue as per the instructions.
21.11.2. Inspectarea Rezultatelor¶
Puteți observa că unele dintre clădirile din dumneavoastră din stratul new_solution au fost “feliate” de instrumentul Intersectare. Acest lucru arată că doar o parte a clădirii - și, prin urmare, doar o parte a proprietății - se află pe terenul potrivit. Prin urmare, putem elimina sensibil acele clădiri din setul nostru de date
21.11.3. Rafinarea Analizei¶
Pentru moment, analiza dvs. ar trebui să arate în felul următor:
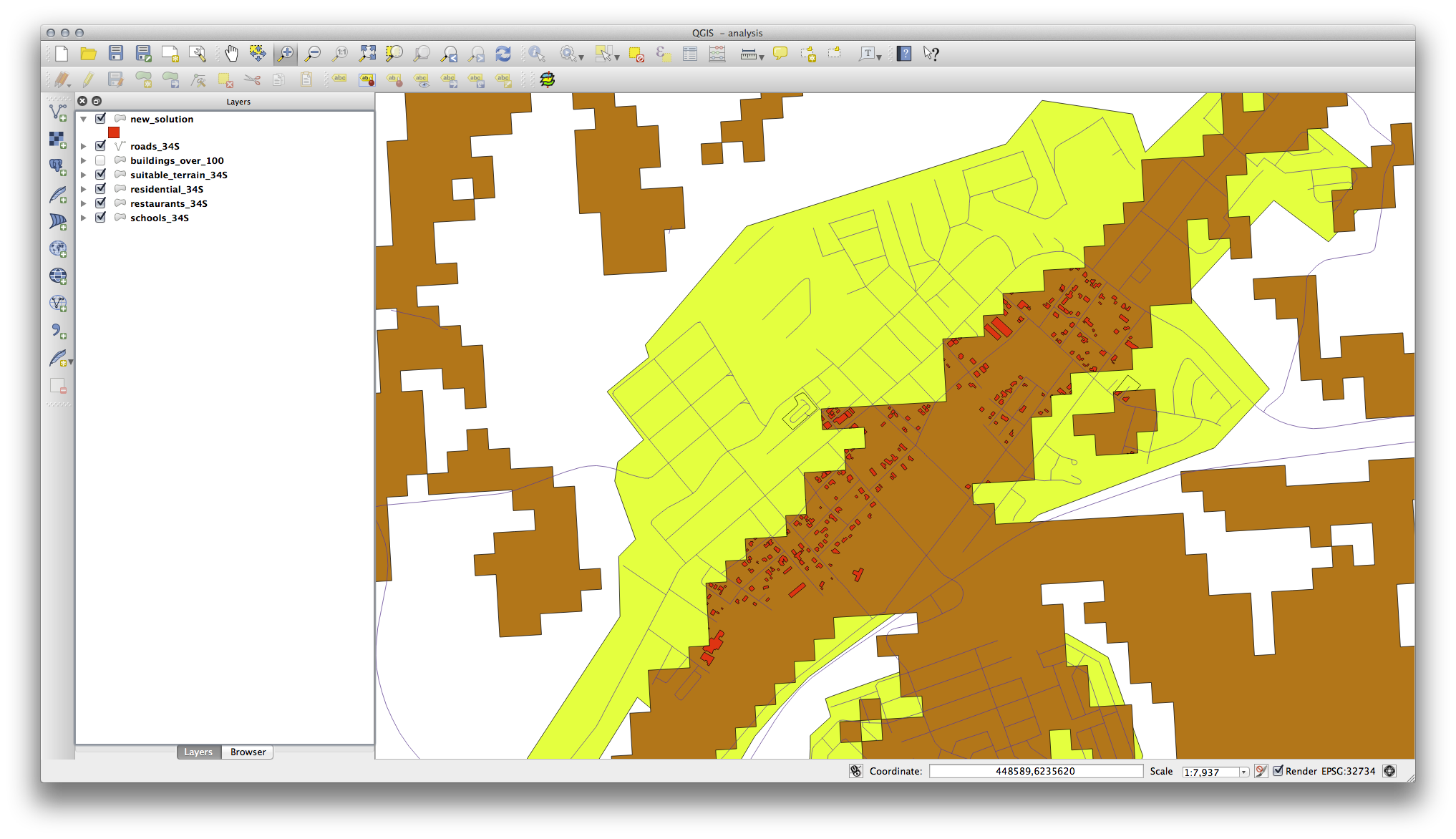
Luați în considerare o zonă circulară, continuă pentru 100 de metri, în toate direcțiile.

În cazul în care raza este mai mare de 100 de metri, prin scăderea a 100 de metri din dimensiunea sa (din toate direcțiile) va rezulta o parte care rămâne în mijloc.
Prin urmare, puteți rula un tampon interior de 100 de metri pe stratul vectorial existent suitable_terrain. În rezultatul funcției tampon, indiferent de ceea ce a mai rămas din stratul original, se vor reprezenta zonele în care există teren potrivit pentru 100 de metri în orice direcție.
Pentru demonstrație:
Mergeți la Vector ‣ Geoprocessing Tools ‣ Buffer(s) pentru a deschide diaolgul Tampo(anelor).
Setați-l astfel:
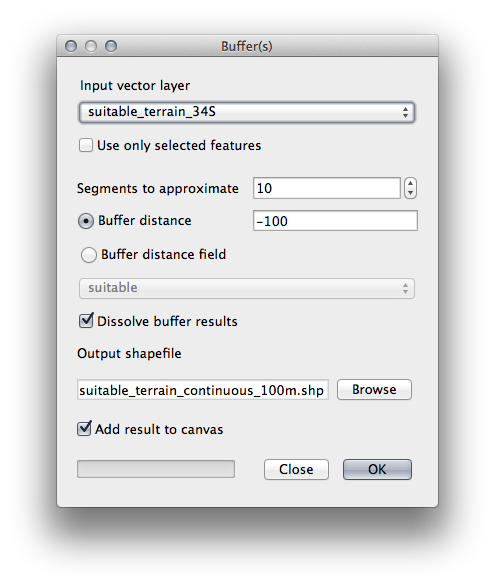
Folosiți stratul suitable_terrain cu 10 segmente și o distanță a tamponului de -100. (Distanța este în mod automat în metri, deoarece harta folosește un CRS proiectat.)
Salvați rezultatul în exercise_data/residential_development/ ca suitable_terrain_continuous100m.shp.
Dacă este necesar, mutați noul strat deasupra stratului original suitable_terrain.
Rezultatele dvs. vor arăta în felul următor:
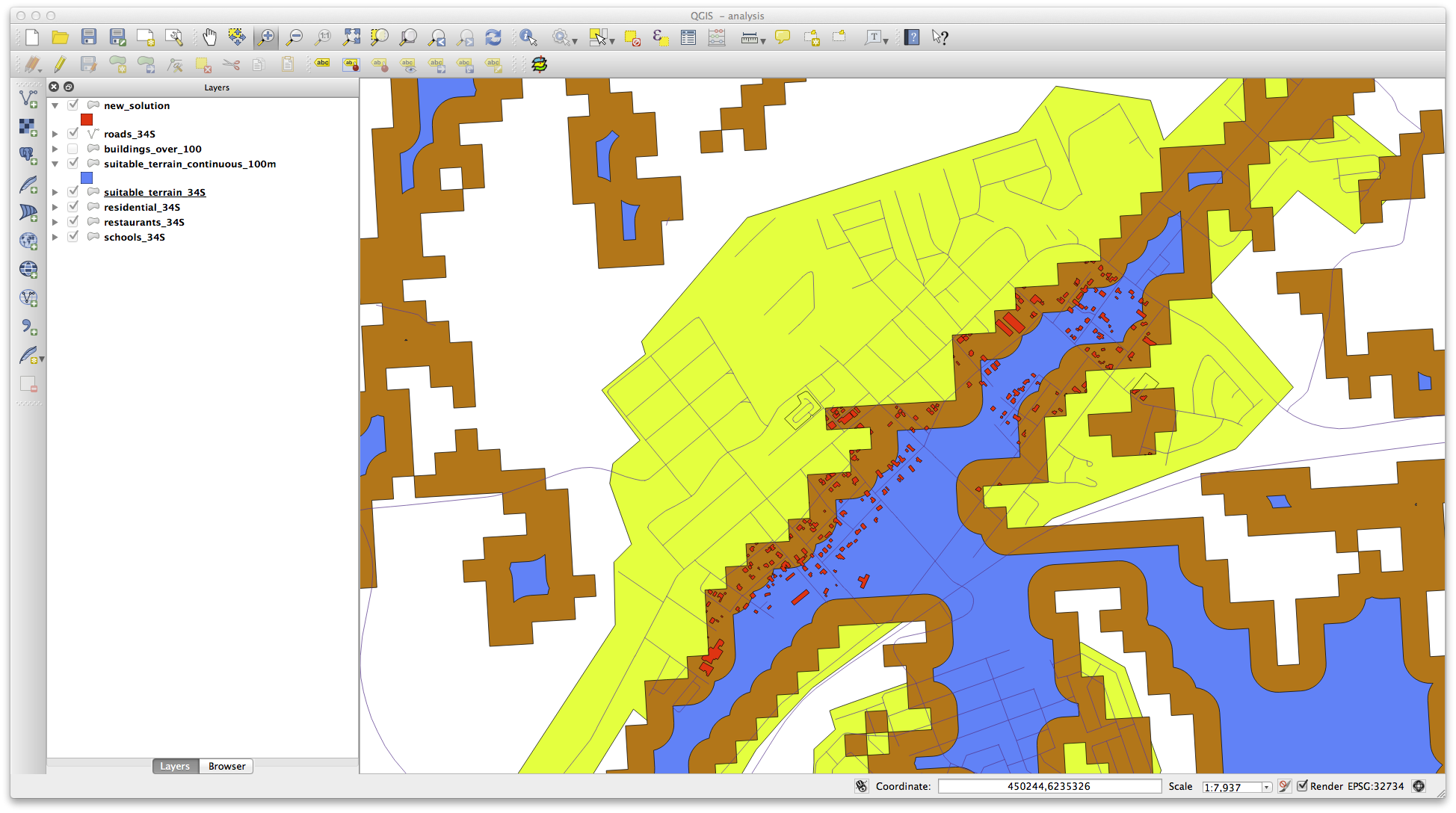
Acum, folosiți instrumentul Selectare după by Locație (Vector ‣ Research Tools ‣ Select by location).
Setați-l astfel:

Selectați entitățile din new_solution care le intersectează pe cele din suitable_terrain_continuous100m.shp.
Acesta este rezultatul:

Sunt selectate clădirile galbene. Deși unele dintre clădiri cad parțial în afara noului strat suitable_terrain_continuous100m, ele se află la fel de bine și în stratul original suitable_terrain și, prin urmare, îndeplinesc toate cerințele noastre.
Salvați selecția în exercise_data/residential_development/ ca final_answer.shp.
21.12. Results For WMS¶
21.12.1. Adăugarea Altui Strat WMS¶
Harta dvs. ar trebui să arate astfel (este posibil să fie necesară reordonarea straturilor):

21.12.2. Adăugarea unui Nou Server WMS¶
Utilizați aceeași abordare ca și mai înainte pentru a adăuga noul server, și stratul corespunzător, așa cum este găzduit pe acel server:


Dacă ați transfocat în zona | majorUrbanName |, veți observa că acest set de date are o rezoluție mică:

Prin urmare, este mai bine să nu utilizați aceste date pentru harta curentă. Datele Blue Marble sunt mult mai potrivite la scări globale sau naționale.
21.12.3. Găsirea unui Server WMS¶
You may notice that many WMS servers are not always available. Sometimes this is temporary, sometimes it is permanent. An example of a WMS server that worked at the time of writing is the World Mineral Deposits WMS at http://apps1.gdr.nrcan.gc.ca/cgi-bin/worldmin_en-ca_ows. It does not require fees or have access constraints, and it is global. Therefore, it does satisfy the requirements. Keep in mind, however, that this is merely an example. There are many other WMS servers to choose from.
21.13. Results For Noțiuni despre Bazele de date¶
21.13.1. Adresarea Tabelei de Properietăți¶
Pentru tabela noastră teoretică de adresare, am putea dori să stocheze următoarele proprietăți:
House Number
Street Name
Suburb Name
City Name
Postcode
Country
La crearea tabelului pentru reprezentarea unui obiect adresă, vom crea coloane pentru a reprezenta fiecare dintre aceste proprietăți și le vom denumi cu nume acceptate de SQL și, eventual, scurtate:
house_number
street_name
suburb
city
postcode
country
21.13.2. Normalizarea Tabelei de Personal¶
Problema majoră a tabelei people rezidă în inexistența unui câmp de adresă singular, care să conțină întreaga adresă a unei persoane. Gândindu-ne la tabela noastră teoretică address de la începutul acestei lecții, știm că o adresă este formată din mai multe proprietăți diferite. Prin stocarea tuturor acestor proprietăți într-un singur câmp, am îngreuna mult actualizarea și interogarea datelor noastre. Prin urmare, trebuie să divizăm câmpul de adresă în diferite proprietăți. Va rezulta, astfel, un tabel cu următoarea structură:
id | name | house_no | street_name | city | phone_no
--+---------------+----------+----------------+------------+-----------------
1 | Tim Sutton | 3 | Buirski Plein | Swellendam | 071 123 123
2 | Horst Duester | 4 | Avenue du Roix | Geneva | 072 121 122
Note
În secțiunea următoare, veți învăța despre relațiile cheilor externe, care ar putea fi utilizate în acest exemplu, pentru a îmbunătăți în continuare structura bazei noastre de date.
21.13.3. Normaliarea Suplimentară a Tabelei de Personal¶
Tabela noastră de personal arată, în mod curent, astfel:
id | name | house_no | street_id | phone_no
---+--------------+----------+-----------+-------------
1 | Horst Duster | 4 | 1 | 072 121 122
Coloana street_id reprezintă o relație ‘una la mai multe’ între obiectul people și obiectul street, care este în tabela streets.
O modalitate de a normaliza și mai mult tabela este de a împărți câmpul în prenume și nume:
id | first_name | last_name | house_no | street_id | phone_no
---+------------+------------+----------+-----------+------------
1 | Horst | Duster | 4 | 1 | 072 121 122
Putem crea, de asemenea, tabele separate pentru numele orașului și al țării, corelându-le cu tabela noastră people, prin intermediul relațiilor ‘una la multe’:
id | first_name | last_name | house_no | street_id | town_id | country_id
---+------------+-----------+----------+-----------+---------+------------
1 | Horst | Duster | 4 | 1 | 2 | 1
O diagramă ER care reprezintă acest lucru ar putea arăta astfel:

21.13.4. Crearea Tabelei de Personal¶
SQL-ul necesar creării tabelei de personal corecte este:
create table people (id serial not null primary key,
name varchar(50),
house_no int not null,
street_id int not null,
phone_no varchar null );
Schema pentru tabel (introduceți \d personal) arată astfel:
Table "public.people"
Column | Type | Modifiers
-----------+-----------------------+-------------------------------------
id | integer | not null default
| | nextval('people_id_seq'::regclass)
name | character varying(50) |
house_no | integer | not null
street_id | integer | not null
phone_no | character varying |
Indexes:
"people_pkey" PRIMARY KEY, btree (id)
Note
În scop ilustrativ, intenționat am omis constrângerea fkey.
21.13.5. Commanda DROP¶
Motivul pentru care comanda DROP nu ar funcționa în acest caz se datorează faptului că tabela people are o constrângere de Cheie Externă în tabela streets. Acest lucru înseamnă că eliminarea (sau ștergerea) tabelei streets ar lăsa tabela people cu referințe către date inexistente despre străzi.
Note
Este posibil să ‘forțăm’ ștergerea tabelului streets cu ajutorul comenzii CASCADE, dar acest lucru ar elimina, de asemenea, tabela people și oricare alta care a avut o relație cu tabela` streets`. Utilizați-o cu prudență!
21.13.6. Inserarea unei Noi Străzi¶
Comanda SQL pe care ar trebui să o utilizați arată astfel (puteți înlocui numele străzii cu altul, la alegere):
insert into streets (name) values ('Low Road');
21.13.7. Adăugarea unei Noi Persoane Cu Relația Cheii Externe¶
Aici este instrucțiunea SQL corectă:
insert into streets (name) values('Main Road');
insert into people (name,house_no, street_id, phone_no)
values ('Joe Smith',55,2,'072 882 33 21');
Dacă priviți iarăși la tabela străzilor (folosind o instrucțiune SELECT ca mai înainte), veți vedea că id-ul pentru intrarea Drumului Principal este 2.
De aceea, am putea mai degrabă doar să introducem numărul 2 de mai sus. Chiar dacă nu vedem Main Road scris integral în intrarea de mai sus, baza de date va fi capabilă să se asocieze valoarea street_id cu 2.
Note
Dacă ați adăugat deja un nou obiect street, ați putea descoperi că noul Drum Principal are ID-ul 3 nu 2.
21.13.8. Returnează Numele Străzilor¶
Aici este instrucțiunea SQL corectă, pe care ar trebui să o folosiți:
select count(people.name), streets.name
from people, streets
where people.street_id=streets.id
group by streets.name;
Rezultatul:
count | name
------+-------------
1 | Low Street
2 | High street
1 | Main Road
(3 rows)
Note
Veți observa că am prefixat numele câmpurilor cu numele tabelei (de exemplu, people.name și streets.name). Acest lucru trebuie să fie făcut de fiecare dată când numele câmpului este ambiguu (de exemplu, când nu este unic în toate tabelele din baza de date).
21.14. Results For Interogări spaţiale¶
21.14.1. Unitățile Folosite în Interogările Spațiale¶
Unitățile utilizate de interogarea din exemplu sunt în grade, deoarece CRS-ul pe care îl folosește stratul este WGS 84. Acesta este un CRS Geografic, ceea ce înseamnă că unitățile sale sunt în grade. Un CRS proiectat, similar proiecțiilor UTM, este în metri.
Amintiți-vă că, atunci când scrieți o interogare, trebuie să cunoașteți CRS-ul stratului. Acest lucru vă va permite să scrieți o interogare care va returna rezultatele pe care le așteptați.
21.14.2. Crearea unui Index Spațial¶
CREATE INDEX cities_geo_idx
ON cities
USING gist (the_geom);
21.15. Results For Construirea Geometriei¶
21.15.1. Crearea Șirurilor de Linii¶
alter table streets add column the_geom geometry;
alter table streets add constraint streets_geom_point_chk check
(st_geometrytype(the_geom) = 'ST_LineString'::text OR the_geom IS NULL);
insert into geometry_columns values ('','public','streets','the_geom',2,4326,
'LINESTRING');
create index streets_geo_idx
on streets
using gist
(the_geom);
21.15.2. Legarea Tabelelor¶
delete from people;
alter table people add column city_id int not null references cities(id);
(captura orașelor în QGIS)
insert into people (name,house_no, street_id, phone_no, city_id, the_geom)
values ('Faulty Towers',
34,
3,
'072 812 31 28',
1,
'SRID=4326;POINT(33 33)');
insert into people (name,house_no, street_id, phone_no, city_id, the_geom)
values ('IP Knightly',
32,
1,
'071 812 31 28',
1,F
'SRID=4326;POINT(32 -34)');
insert into people (name,house_no, street_id, phone_no, city_id, the_geom)
values ('Rusty Bedsprings',
39,
1,
'071 822 31 28',
1,
'SRID=4326;POINT(34 -34)');
Dacă ați obținut următorul mesaj de eroare:
ERROR: insert or update on table "people" violates foreign key constraint
"people_city_id_fkey"
DETAIL: Key (city_id)=(1) is not present in table "cities".
atunci înseamnă că în timp ce experimentați crearea poligoanelor pentru tabela orașelor, trebuie să fi șters unele dintre ele și să fi reînceput. Doar verificați intrările din tabelul de orașe și folosiți orice id care există.
21.16. Results For Modelul Entității Simple¶
21.16.1. Popularea Tabelelor¶
create table cities (id serial not null primary key,
name varchar(50),
the_geom geometry not null);
alter table cities
add constraint cities_geom_point_chk
check (st_geometrytype(the_geom) = 'ST_Polygon'::text );
21.16.2. Popularea Tabelei Geometry_Columns¶
insert into geometry_columns values
('','public','cities','the_geom',2,4326,'POLYGON');
21.16.3. Adăugarea Geometriei¶
select people.name,
streets.name as street_name,
st_astext(people.the_geom) as geometry
from streets, people
where people.street_id=streets.id;
Rezultatul:
name | street_name | geometry
--------------+-------------+---------------
Roger Jones | High street |
Sally Norman | High street |
Jane Smith | Main Road |
Joe Bloggs | Low Street |
Fault Towers | Main Road | POINT(33 -33)
(5 rows)
După cum puteți vedea, constrângerea noastră permite null-uri care urmează să fie adăugate în baza de date.