18.16. 水文解析¶
ノート
このレッスンでは、ちょっとした水文解析を実行します。この分析は解析ワークフローの非常に良い例を構成しているので、後のいくつかのレッスンの一部に使用されます。そして、いくつかの高度な機能を発揮するためにそれを使用します。
このレッスンでは、ちょっとした水文解析をしていきます。DEM を皮切りに、水路ネットワークを抽出し、流域を描き、いくつかの統計を計算していきます。
最初は、レッスンデータ、DEM だけが含まれている、を持つプロジェクトをロードすることです。
実行する最初のモジュールは 流域面積 です (一部SAGAバージョンではそれは 累積流量(トップダウン) と呼ばれる) 。 流域面積 という名前の他の誰にも使用できます。それらは下では異なるアルゴリズムを持っているが、結果は基本的に同じです。
標高 フィールドにDEMを選択し、残りのパラメーターはデフォルト値のままにします。

アルゴリズムには複数のレイヤーを計算するものもありますが、 流域 レイヤーだけが使用する予定のレイヤーです。
ご希望なら他のレイヤーは取り除くことができます。
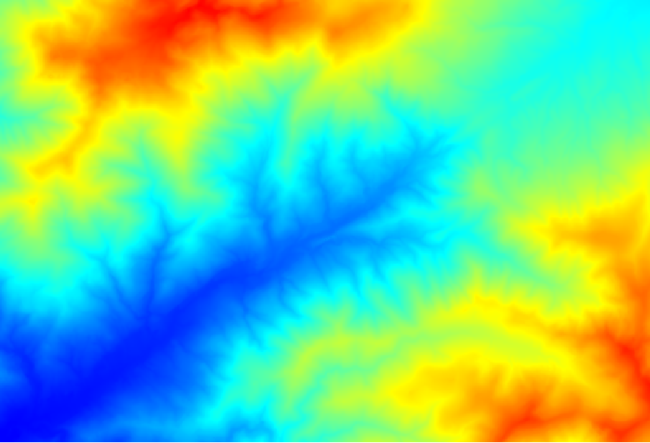
レイヤーのレンダリングは非常に有益ではありません。

To know why, you can have a look at the histogram and you will see that values are not evenly distributed (there are a few cells with very high value, those corresponding to the channel network). Calculating the logarithm of the catchment area value yields a layer that conveys much more information (you can do it using the raster calculator).

流域(累積流量とも言われる) は、水路開始のためのしきい値を設定するために使用できます。これは、 水路ネットワーク アルゴリズムを使用して行うことができます。それを設定しなければならない方法はこうなります ( 開始しきい値 が10.000.000 より大きい ことに注意してください) 。

元々の集水域レイヤー、対数のではないレイヤーを使用してください。対数のレイヤーはレンダリングする目的だけのためでした。
開始しきい値 を増やすと、より疎らな水路ネットワークが得られます。減らすと、より密なネットワークが得られます。提案された値では、得られるものはこれです。

上の画像は得られたベクターレイヤーとDEMだけ表示していますが、同じ水路ネットワークを持つラスターのレイヤーがなければなりません。そのラスターレイヤーが、実際には、使用しているものになります。
さてここで、吐出口ポイントとしてその中のすべての接合部を使用して、その水路のネットワークに対応する下位流域を描写する 流域の流域 アルゴリズムを使用します。これは、対応するパラメーターダイアログボックスをどのように設定する必要があるかです。

そして、得られるものはこれです。

これがラスターの結果です。それは グリッドクラスをベクター化 アルゴリズムを使用してベクター化できます。


さて、下位流域の一つで標高値についての統計を計算してみましょう。考え方は、ちょうどその下位流域内だけの標高を表しているレイヤーを得て、それをそれらの統計を計算するモジュールに渡すことです。
まずは、下位流域を表すポリゴンと元DEMをクリップしましょう。 ポリゴンでラスターをクリップ アルゴリズムを使用します。単一の下位流域ポリゴンを選択し、クリッピングアルゴリズムを呼び出す場合、アルゴリズムが選択を知っているので、そのポリゴンによってカバーされる領域にDEMをクリップできます。
ポリゴンを選択し、

そして次のパラメーターを使用してクリッピングアルゴリズムを呼び出します。
入力フィールドに選択された要素が、もちろん、クリップしたいDEMです。
このようなものが得られます。

このレイヤーは、 ラスターレイヤー統計 アルゴリズムで使用できるようになりました。

結果の統計は以下のものです。

他のレッスンでは流域の計算手順および統計計算の両方を使用するでしょう。そして他の要素がそれらの両方を自動化しより効率的に作業するのにどのように役立ちうるかを見ます。