7.4. Lesson: Estadísticas Espaciales¶
Nota
Lección desarrollada por Linfiniti y S Motala (Universidad Tecnológica de Península del Cabo)
Las estadísticas espaciales te permiten entender que está pasando en un conjunto de datos vectoriales dado. QGIS incluye muchas herramientas estándar para análisis estadísticos que demuestran ser muy útiles para estas materias.
El objetivo de esta lección: Saber como utilizar las herramientas estadísticas espaciales de QGIS.
7.4.1.  Follow Along: Crear un Conjunto de Datos de Prueba¶
Follow Along: Crear un Conjunto de Datos de Prueba¶
Para obtener un conjunto de datos con el que trabajar, crearemos un conjunto de puntos al azar.
Para ello, necesitarás un conjunto de datos poligonal para definir la extensión del área en la que quieres crear los puntos.
Utilizaremos el área cubierta por calles.
Crea un mapa vacío nuevo.
Añade tu capa roads_34S, así como el ráster srtm_41_19.tif (datos de elevaciones) que s encuentran en exercise_data/raster/SRTM/.
Nota
Puedes encontrar que tu SRTM MDE tiene un SRC diferente que el de la capa de carreteras. En ese caso, puedes reproyectar la capa de carreteras o la del MDE utilizando las técnicas aprendidas anteriormente en este módulo.
Utiliza la herramienta Envolvente(s) convexa(s) (disponible en Vectorial ‣ Herramientas de geoproceso) para generar un área conteniendo todas las calles:

Guárdalo como envolvente_carreteras.shp en exercise_data/spatial_statistics/.
Marque a opção Adicionar resultado na tela para adicionar a saída para o TOC (Lista de camadas).
7.4.1.1. Creación de puntos al azar¶
Crea puntos al azar en el área utilizando la herramienta en Vectorial ‣ Herramientas de investigación ‣ Puntos aleatorios:

Guárdalo en exercise_data/spatial_statistics/ como puntos_aleatorios.shp.
Marque a opção Adicionar resultado na tela para adicionar a saída para o TOC (Lista de camadas).

7.4.1.2. Muestreo de los datos¶
Para crear un conjunto de datos de muestreo desde el raster, necesitarás utilizar el plugin Point sampling tool.
Refiérete al módulo de complementos si es necesario.
Busca la frase point sampling en el Complementos –> Administrar e instalar complementos... y encontrarás el complemento.
Tan pronto como la actives en el Administrador de complementos, encontrarás la herramienta en Complementos ‣ Analyses ‣ Point sampling tool:
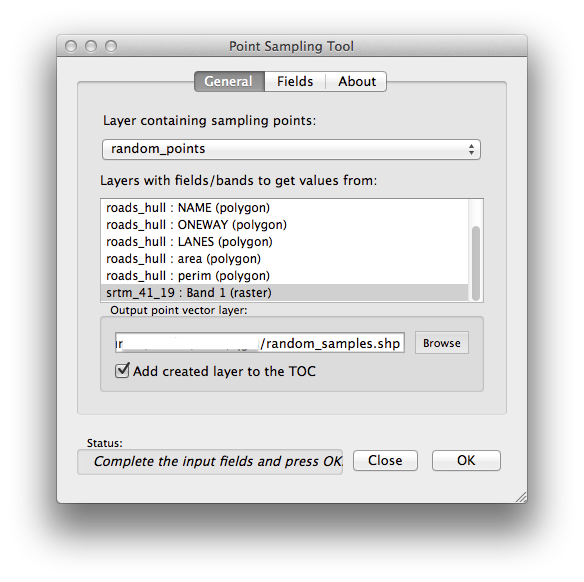
Selecciona puntos_aleatorios como la capa contenedora de puntos de muestreo, y el SRTM raster como la banda de la que se obtengan los valores.
Asegúrate de que “Add created layer to the TOC” está habilitado.
Guardalo en exercise_data/spatial_statistics/ como muestras_aleatorias.shp.
Ahora puedes comprobar los datos muestreados del archivo ráster en la tabla de atributos de la capa muestras_aleatorias, estarán en una columna llamada srtm_41_19.tif.
Aquí tienes una posible capa de muestreo:
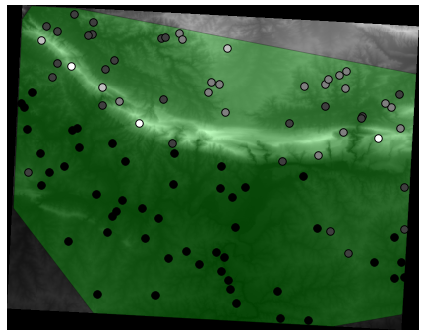
Los puntos de muestreo están clasificados por su valor como los puntos oscuros lo son a baja altitud.
Utilizarás esta capa de datos de muestreo durante el resto de los ejercicios estadísticos.
7.4.2. Follow Along: Estadísticas Básicas¶
Ahora obtén lsa estadísticas básica de esta capa.
Haz clic en la entrada del menú Vectorial ‣ Herramientas de analisis ‣ Estadísticas básicas.
En el cuadro de diálogo que aparece, especifíca la capa muestras_aleatorias como fuente.
Asegurate de que Campo objeto esta ajustado a srtm_41_19.tif que es el campo para el que calcularás las estadísticas.
Haz clic en Aceptar. Obtendrás resultados como estos:

Nota
Puedes copiar y pegar los resultados en una hoja de cálculo. Los datos utilizan como separador (dos puntos :).

Cierra el cuadro de diálogo del plugin cuando acabes.
Para entender las estadísticas anteriores, mira esta lista de definiciones:
- Media
La media (promedio) es simplemente la suma de los valores dividido por el número de valores.
- Dev. Est.
La desviación estándar. Da una indicación de cómo de cerca se agrupan los valores alrededor de la media. Cuanto menor sea la desviación estándar, más cerca estarán los valores a la media.
- Suma
Todos los valores sumados.
- Mín
El valor mínimo
- Máx
El valor máximo.
- N
Número de muestras/valores.
- CV
La covarianza espacial covarianza del conjunto de datos.
- Número de valores únicos
El número de valores que son únicos en el conjunto de datos. Si hay 90 datos únicos en un conjunto de datos con N=100, entonces los restantes 10 valores son iguales a uno o más de los otros.
- Intervalo
La diferencia entre los valores mínimo y máximo.
- Mediana
Si organizas todos los valores de menor a mayor, el valor en el medio (o la media de los dos valores en el medio, si N es un número par) es la mediana de los valores.
7.4.3. Follow Along: Cálculo de una Matriz de Distancia¶
Crea una nueva capa de puntos en la misma proyección que los demás conjuntos de datos (WGS 84 / UTM 34S).
Entra en el modo edición y digitaliza tres puntos en en algún lugar entre los otros puntos.
Como alternativa, utiliza el mismo método de generación de punto al azar como antes, pero especifica sólo tres puntos.
Guarda tu nueva capa como puntos_distancia.shp.
Para generar una matriz de distancia utilizando esos puntos:
Abre la herramienta Vectorial ‣ Herramientas de análisis ‣ Matriz de distancia.
Selecciona la capa puntos_distancia como capa de entrada, y la capa muestras_aleatorias como capa de destino.
Ajústalo así:

Guarda el resultado como matriz_distancia.csv.
Haz clic en Aceptar para generar la matriz de distancia.
Abre un programa de hoja de cálculo para ver los resultados. Aquí tienes un ejemplo:

7.4.4. Follow Along: Análisis del Vecinos más Próximos¶
Para hacer un análisis de vecinos más próximos:
Haz clic en el elemento del menú Vectorial ‣ Herramientas de análisis ‣ Análisis de vecinos más próximos.
En el cuadro de diálogo que aparece, selecciona la capa muestras_aleatorias y haz clic en Aceptar.
Los resultados aparecerán en el cuadro de diálogo de la ventana de texto, por ejemplo:
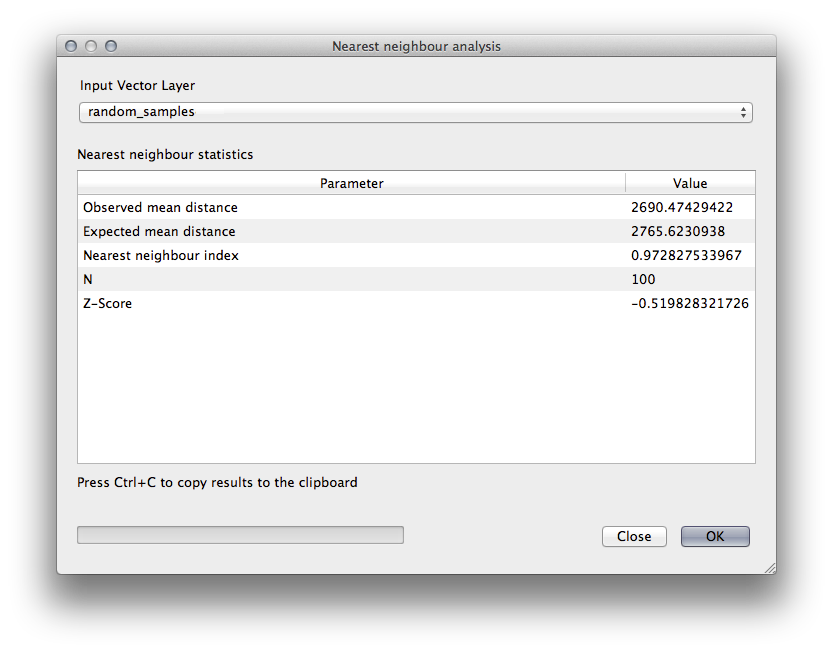
Nota
Puedes copiar y pegar los resultados en una hoja de cálculo. Los datos utilizan como separador (dos puntos :).
7.4.5. Follow Along: Coordenadas Medias¶
Para obtener las coordenadas medias de un conjunto de datos:
Haz clic en el elemento del menú Vectorial ‣ Herramientas de análisis ‣ Coordenada(s) media.
En el cuadro de diálogo que aparece, especifica muestras_aleatorias como la capa de entrada, pero deja las elecciones opcionales sin cambiar.
Especifica la capa de destino como coord_medias.shp.
Haz clic en Aceptar.
Añade la capa a la Lista de capas cuando se solicite.
Compara estas con la coordenada central del polígono que fue utilizada para crear la muestra aleatoria.
Haz clic en el elemento del menú Vectorial ‣ Herramientas de geometría ‣ Centroides de polígonos.
En el cuadro de diálogo que aparece, selecciona envolvente_carreteras como la capa de entrada.
Guarda el resultado como punto_central.
Añadelo a la Lista de capas cuando se solicite.
Como puedes ver en el ejemplo siguiente, las coordenadas medias y el centro del área de estudio (en naranja) no coinciden necesariamente:

7.4.6. Follow Along: Histogramas de Imagenes¶
El histograma de un conjunto de datos muestra la distribución de sus valores. La forma más simple de demostrarlo en QGIS es a través de la histograma de imagen, disponible en el cuadro de diálogo Propieadades de la capa de cualquier capa imagen.
En tu Lista de capas, haz clic derecho en la capa SRTM DEM.
Selecciona Propiedades.
Elige la pestaña Histograma. Puede que necesites clicar en el botón Calcular Histograma para generar un gráfico. Verás un gráfico describiendo la frecuencia de los valores en la imagen.
Puedes exportarlo como una imagen:

Selecciona la pestaña Metadata, puedes ver información más detallada dentro de la caja Propiedades.
El valor medio es 332.8, ¡y el valor máximo es 1699! Pero esos valores no se muestran en el histograma. ¿Por qué no? Porque hay muy pocos, comparado con la abundancia de píxels con valores por debajo de la media. Por eso el histograma se extiende tan lejos hacia la derecha, incluso hay una línea no visible marcando la frecuencia de valores mayores que 250.
Además, ten presente que el histograma te muestra la distribución de los valores, y no todos los valores son necesariamente visibles en el gráfico.
(Puedes cerrar ahora las Propiedades de la capa.)
7.4.7. Follow Along: Interpolación Espacial¶
Digamos que tienes una colección de puntos de muestra de los que te gustaría extrapolar datos. Por ejemplo, puede que tengas acceso al conjunto de datos muestras_aleatorias que creaste antes, y quieres tener una idea de que aspecto tiene el terreno.
Para empezar, inicia el Cuadrícula (Interpolación) clicando en el elemento del menú Ráster ‣ Análisis‣ Cuadrícula (Interpolación).
En el campo Archivo de entrada, selecciona muestras_aleatorias.
Comprueba la caja Campo Z, y selecciona el campo srtm_41_19.
Ajusta la situación de Archivo de salida a exercise_data/spatial_statistics/interpolacion.tif.
Comprueba la caja Algoritmo y selecciona Distancia inversa a una potencia.
Ajusta el Potencia a 5.0 y el Suavizado a 2.0. Deja los otros valores como están.
Comprueba la caja Cargar en la vista del mapa cuando se termine y haz clic en Aceptar.
Cuando esté hecho, haz clic en Aceptar en el cuadro de diálogo que dice Proceso completado, haz clic en Aceptar en el diálogo que muestra la información de retorno (si ha aparecido), u haz clic en Cerrar del cuadro de diálogo Cuadrícula (Interpolación).
Aquí se compara el conjunto de datos original (izquierda) y el construido por nuestros puntos de muestreo (derecha). El tuyo puede parecer diferente debido a la forma aleatoria de situación y puntos de muestreo.

Como puedes ver, 100 puntos de muestreo no son realmente suficientes para tener una impresión detallada del terreno. Te dan una idea muy general, pero también puede ser engañoso. Por ejemplo, en la imagen anterior, no está claro que hay una montaña alta que discurre de este a oeste; sin embargo, la imagen parece mostrar un valle, con puntos altos en el oeste. Simplemente utilizando una inspección visual, podemos ver que el conjunto de datos de muestreo no es representativo del territorio.
7.4.8.  Try Yourself¶
Try Yourself¶
Utiliza los procesos mostrados antes para crear un nuevo conjunto de datos aleatorios de 1000.
Utiliza los puntos para muestrear el DEM original.
Utiliza la herramienta Cuadrícula (Interpolación) en el nuevo conjunto de datos como antes.
Nombra al archivo de salida interpolacion_1000.tif, con Potencia y Suavizado ajustado a 5.0 y 2.0, respectivamente.
Los resultados (dependiendo de la posición de tus puntos aleatorios) se verán más o menos como esto:

El borde muestra la capa envolvente_carreteras (que representa los límites de puntos aleatorios de muestreo) para explicar una repentina falta de detalle más allá de sus bordes. Esto es una representación mucho mejor del terreno, debido a la mayor densidad de puntos de muestreo.
Aquí hay un ejemplo del aspecto con puntos de muestreo de 10 000:

Nota
No es recomendable que intentes hacer esto con 10 000 puntos de muestreo si no estás trabajando con un ordenador rápido, ya que con ese tamaño de conjunto de datos de muestreo se requiere mucho más tiempo de procesado.
7.4.9. Follow Along: Herramientas Adicionales de Análisis Espacial¶
Originalmente un proyecto separado y luego accesible como complemento, el software SEXANTE se ha añadido al QGIS como una función básica desde la versión 2.0. Puedes encontrarlo como un menú QGIS nuevo con su nuevo nombre Procesado desde donde puedes acceder a una caja de herramientas rica en herramientas de análisis espacial que te permiten acceder a varios complementos desde una simple interfaz.
Ative este conjunto de ferramentas, permitindo a entrada do menu Processamento ‣ Caixa de Ferramentas. A caixa de ferramentas parece como essa:

Es probable que la veas anclada en QGIS en la parte derecha del mapa. Observa que las herramientas listadas ahí son enlaces a las herramientas. Algunos de ellos son algoritmos propios de SEXTANTE y otros son enlaces de herramientas a las que se accede desde aplicaciones externas como GRASS, SAGA o la caja de herramientas Orfeo. Estas aplicaciones externas están instaladas con QGIS así que ya puedes utilizarlas. En caso de que necesites cambiar la configuración de las herramientas de Procesado, o por ejemplo, necesites actualizar una nueva versión de una de la aplicaciones externas, puedes acceder a sus ajustes desde Procesado ‣ Opciones y configuración.
7.4.10. Follow Along: Análisis de Patrones Espaciales de Puntos¶
Para una simple indicación de la distribución espacial de puntos en el conjunto de datos muestras_aleatorias, podemos utilizar la herramienta de SAGA Spatial Point Pattern Analysis a través de la Caja de herramientas de procesado que abriste antes.
En Caja de herramientas de procesado, busca la herramienta Spatial Point Pattern Analysis.
Haz doble clic en él para abrir el cuadro de diálogo.
7.4.10.1. Instalando SAGA¶
Nota
Si SAGA no está instalado en tu sistema, el cuadro de diálogo del complemento te informará que la dependencia no se encuentra. Si éste no es el caso, puedes saltarte estos pasos.
7.4.10.2. En Windows¶
Encontrarás una instalación de SAGA para Windows en los materiales del curso.
Inicia el programa y sigue sus instrucciones para instalar SAGA en tu sistema de Windows. ¡Anota la ruta en la que lo estás instalando!
Una vez instalado el SAGA, necesitarás configurar SEXTANTE para encontrar la ruta en el que estaba instalado.
Haz clic en la entrada del menú Analysis ‣ SAGA options and configuration.
En el cuadro de diálogo que aparece, expande SAGA item and look for SAGA folder. Su valor estará en blanco.
En ese espacio, inserta la ruta donde instalaste el SAGA.
7.4.10.3. En Ubuntu¶
Busca SAGA GIS en el Software Center, o introduce la frase sudo apt-get install saga-gis en tu terminal. (Puede que necesites primero añadir un repositorio de SAGA en tus fuentes.)
QGIS encontrará SAGA automáticamente, aunque puede que necesites reiniciar QGIS si no funciona directamente.
7.4.10.4. En Mac¶
Los usuarios Homebrew pueden instalar SAGA con este comando:
instalación brew del saga básico
Si no utilizas Homebrew, sigue las instrucciones siguientes:
http://sourceforge.net/apps/trac/saga-gis/wiki/Compiling%20SAGA%20on%20Mac%20OS%20X
7.4.10.5. Después de instalar¶
Ahora que has instalado y configurado SAGA, sus funciones te serán accesibles.
7.4.10.6. Utilizando SAGA¶
Abre un cuadro de diálogo del SAGA.
SAGA produce tres salidas, así que requiere tres rutas de salida.
Guarda esas tres salidas en exercise_data/spatial_statistics/, utilizando los nombres de archivo que creas conveniente.

La salida se verá así (la simbología se cambió para este ejemplo):
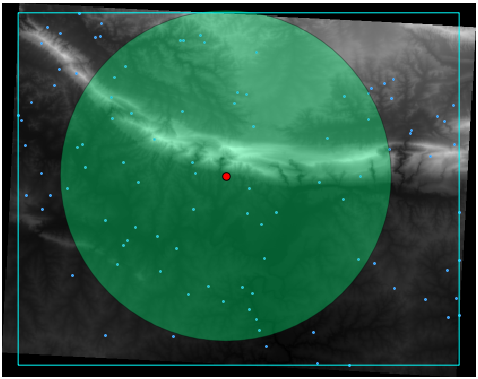
El punto rojo es la media central; el gran círculo es la distancia estándar, que dá una indicación de cómo de cerca estan distribuidos los puntos alrededor de la media central; y el rectángulo es la caja delimitadora, describiendo el mínimo rectángulo posible que todavía incluye todos los puntos.
7.4.11. Follow Along: Análisis de la Distancia Mínima¶
A menudo, la salida de un algoritmo no es un archivo shape, sino una tabla resumen de las propiedades estadísticas del conjunto de datos. Una de esas herramientas es Minimum Distance Analysis.
Encontre esta ferramenta no Caixa de Ferramentas Processamento como Analise de Distância Mínima.
No requiere ninguna otra entrada a parte de especificar el conjunto de puntos vectoriales a ser analizado.
Escoge el conjunto de datos puntos_aleatorios.
Haz clic en Aceptar. Al finalizar, una tabla DBF aparecerá en la Lista de capas.
Selecciónala, luego abre su tabla de atributos. Aunque algunas figuras puede que varíen, tus resultados estarán en este formato:

7.4.12. In Conclusion¶
QGIS permite muchas posibilidades para analizar las propiedades espaciales estadísticas de conjuntos de datos.
7.4.13. What’s Next?¶
Ahora que has cubierto los análisis vectoriales, ¿Por qué no ver qué se puede hacer con rasters? ¡Eso es lo que haremos en el próximo módulo!