7.4. Lesson: 공간 통계¶
주석
이 강의는 Linfiniti와 S. Motala(남아프리카공화국 케이프 페닌슐라 기술대학교)가 작성했습니다.
공간 통계를 이용하면 주어진 벡터 데이터셋이 어떤 의미인지 분석하고 이해할 수 있습니다. QGIS는 이런 목적에 대해 유용하다고 알려진 몇몇 표준 통계 분석 도구를 포함하고 있습니다.
이 강의의 목표: QGIS의 공간 통계 도구 사용 방법을 배우기.
7.4.1.  Follow Along: 테스트용 데이터셋 생성¶
Follow Along: 테스트용 데이터셋 생성¶
강의에서 사용할 포인트 데이터셋을 얻기 위해, 랜덤한 포인트들을 생성해보겠습니다.
이 때 포인트를 생성하려는 구역의 범위를 정의하는 폴리곤 데이터셋이 필요합니다.
거리들이 차지한 구역을 사용하겠습니다.
비어 있는 새 맵을 생성하십시오.
roads_34S레이어는 물론,exercise_data/raster/SRTM/경로에 있는srtm_41_19.tif래스터(고도 데이터)를 추가하십시오.
주석
SRTM DEM 레이어의 CRS가 도로 레이어와 다를 수도 있습니다. 이럴 경우, 이 모듈의 이전 강의에서 배운 기술을 이용, 도로나 DEM 레이어 가운데 하나를 재투영할 수 있습니다.
Vector ‣ Geoprocessing Tools 메뉴에 있는 Convex hull(s) 도구를 이용해서 다음과 같이 모든 도로를 전부 감싸는 구역을 생성합니다.
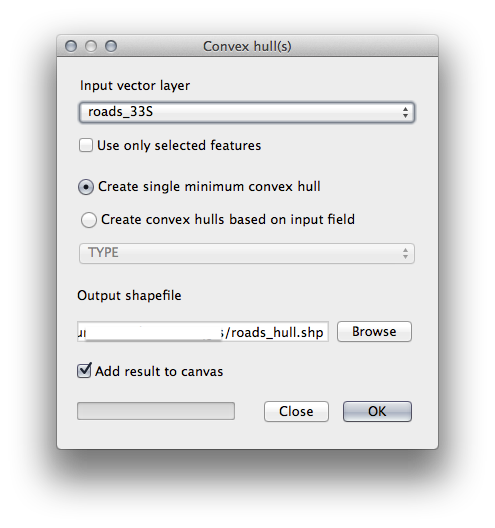
산출물을
exercise_data/spatial_statistics/디렉터리에roads_hull.shp파일로 저장하십시오.산출물을 TOC (Layers list)에 추가하도록 Add result to canvas 옵션을 체크하십시오.
7.4.1.1. 랜덤한 포인트 생성¶
메뉴에서 Vector ‣ Research Tools ‣ Random points 도구를 이용, 다음과 같이 이 구역 안에 포인트를 랜덤하게 생성합니다.

산출물을
exercise_data/spatial_statistics/디렉터리에random_points.shp파일로 저장하십시오.산출물을 TOC (Layers list)에 추가하도록 Add result to canvas 옵션을 체크하십시오.

7.4.1.2. 데이터 샘플링¶
래스터에서 샘플 데이터셋을 생성하려면 Point sampling tool 플러그인을 이용해야 합니다.
필요한 경우 플러그인에 대한 강의를 미리 보는 것도 좋습니다.
Plugin –> Manage and Install Plugins... 에서
point sampling이라는 구절을 검색해서 플러그인을 찾을 수 있습니다.Plugin Manager 로 이 도구를 활성화시키면, 메뉴의 Plugins ‣ Analyses ‣ Point sampling tool 항목으로 다음과 같은 도구를 실행할 수 있습니다.
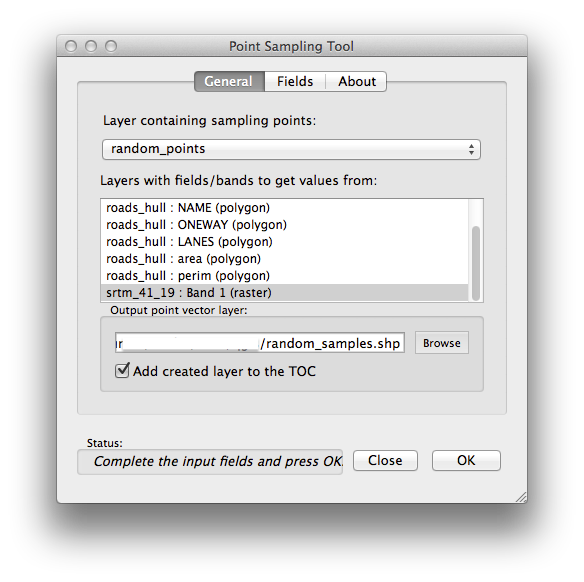
샘플링할 포인트를 담은 레이어로 random_points 를, 값을 추출할 밴드로 SRTM 래스터를 선택합니다.
“Add created layer to the TOC” 항목이 체크되어 있는지 확인하십시오.
산출물을
exercise_data/spatial_statistics/디렉터리에random_samples.shp파일로 저장하십시오.
이제 random_samples 레이어의 속성 테이블에서 래스터 파일로부터 샘플링한 데이터를 확인할 수 있습니다. srtm_41_19.tif 이라는 명칭의 열에 데이터가 있을 것입니다.
다음과 비슷한 샘플 레이어가 보일 것입니다.

샘플 포인트는 각각의 값에 따라 범주화됩니다. 이 경우 포인트의 고도가 낮을수록 색이 어두워집니다.
나머지 통계 실습 동안 이 샘플 레이어를 사용할 것입니다.
7.4.2. Follow Along: 기본 통계¶
이제 이 레이어에 대한 기본적인 통계를 내보겠습니다.
메뉴에서 Vector ‣ Analysis Tools ‣ Basic statistics 항목을 클릭하십시오.
대화 창이 뜨면 입력 레이어로 random_samples 를 설정합니다.
Target field 가 여러분이 통계를 계산할 대상인
srtm_41_19.tif으로 설정돼 있는지 확인하십시오.OK 를 클릭합니다. 다음과 같은 결과를 보게 될 것입니다.
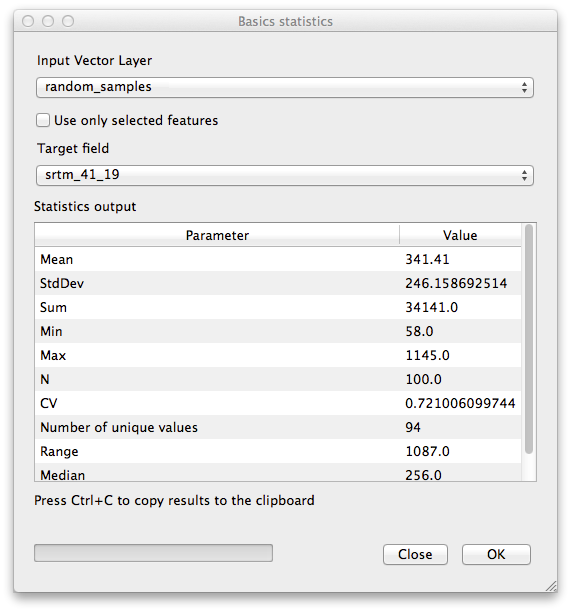
주석
이 결과를 스프레드시트에 복사 & 붙여넣기 할 수 있습니다. 이 데이터는 구분자로 쌍점 : 을 사용합니다.

완료되면 플러그인 대화 창을 닫으십시오.
이 통계를 이해하려면 다음 정의들을 참조하십시오.
- Mean
중간(평균)값은 값을 모두 더한 것을 값의 개수로 나눈 값입니다.
- StdDev
표준편차입니다. 값들이 얼마나 중간값에 가까이 모여 있는지를 나타냅니다. 표준편차가 작을수록 값들이 중간값에 더 가까이 모이는 경향이 있습니다.
- Sum
모든 값들을 더한 값입니다.
- Min
최소값입니다.
- Max
최대값입니다.
- N
샘플/값의 개수입니다.
- CV
- Number of unique values
이 데이터셋에서 유일한 값의 개수입니다. N=100 인 데이터셋에 90개의 유일한 값이 있을 경우, 나머지 10개의 값은 서로 하나 이상 같습니다.
- Range
최소/최대값의 차이입니다.
- Median
모든 값을 최소에서 최대로 배열할 경우, 그 중앙에 있는 (또는 N이 짝수라면 두 중앙값의 평균) 값을 중앙값이라 합니다.
7.4.3. Follow Along: 거리 행렬 계산¶
다른 데이터셋(
WGS 84 / UTM 34S)과 동일한 투영체로 새 포인트 레이어를 생성하십시오.편집 모드로 들어가서 다른 포인트들 사이 어딘가에 포인트 3개를 디지타이즈하십시오.
또는 이전과 마찬가지 방법으로 랜덤한 포인트를 생성하되 딱 3개만 설정하십시오.
이 새 레이어를
distance_points.shp파일로 저장합니다.
이 포인트들로 거리 행렬을 생성하는 방법은 다음과 같습니다.
Vector ‣ Analysis Tools ‣ Distance matrix 도구를 실행합니다.
입력 레이어로 distance_points 레이어를, 목표 레이어로 random_samples 레이어를 선택합니다.
다음과 같이 설정하십시오.
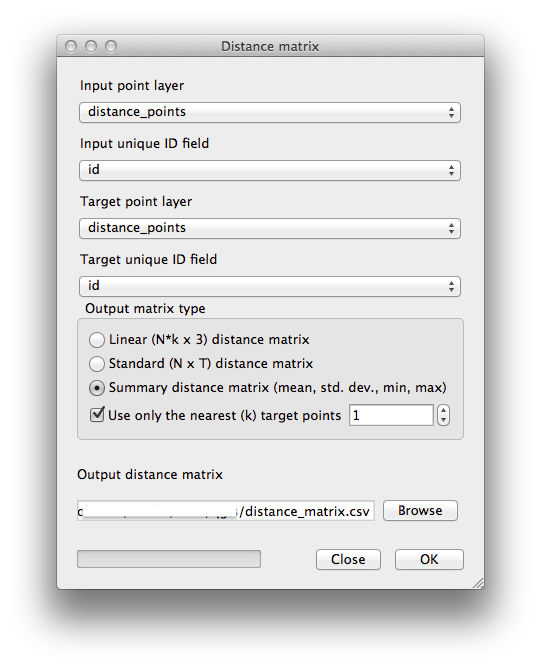
산출물을
distance_matrix.csv파일로 저장하도록 지정하십시오.OK 를 클릭해서 거리 행렬을 생성합니다.
스프레드시트 프로그램으로 산출물 파일을 열어보십시오. 다음과 비슷한 결과를 볼 수 있습니다.

7.4.4. Follow Along: 가장 가까운 이웃 분석¶
가장 가까운 이웃 분석을 하려면,
메뉴에서 Vector ‣ Analysis Tools ‣ Nearest neighbor analysis 항목을 클릭하십시오.
대화 창이 뜨면 random_samples 레이어를 선택한 다음 OK 를 클릭하십시오.
대화 창의 텍스트 창에 다음과 비슷한 결과가 나타날 것입니다.

주석
이 결과를 스프레드시트에 복사 & 붙여넣기 할 수 있습니다. 이 데이터는 구분자로 쌍점 : 을 사용합니다.
7.4.5. Follow Along: 평균 좌표¶
데이터의 평균 좌표를 얻으려면,
메뉴의 Vector ‣ Analysis Tools ‣ Mean coordinate(s) 항목을 클릭하십시오.
대화 창이 뜨면 입력 레이어로 random_samples 를 설정하되 다른 옵션들은 변경하지 마십시오.
산출 레이어로
mean_coords.shp파일을 설정하십시오.OK 를 클릭합니다.
질문이 뜨면 Layers list 에 해당 레이어를 추가합니다.
이 레이어를 랜덤 샘플을 생성하는 데 쓰인 폴리곤의 중앙 좌표와 비교해봅시다.
메뉴에서 Vector ‣ Geometry Tools ‣ Polygon centroids 항목을 클릭하십시오.
대화 창이 뜨면 입력 레이어로 roads_hull 을 선택하십시오.
결과물을
center_point로 저장하십시오.질문이 뜨면 Layers list 에 해당 레이어를 추가합니다.
다음 그림에서 볼 수 있듯이, 평균 좌표와 연구 지역의 중앙 좌표(오렌지색)는 반드시 일치하지 않을 수도 있습니다.

7.4.6. Follow Along: 이미지 히스토그램¶
데이터셋의 히스토그램은 데이터셋의 값들의 분포를 보여줍니다. QGIS에서 이를 보여줄 수 있는 가장 간단한 방법은 이미지 레이어의 Layer Properties 대화 창에서 쓸 수 있는 이미지 히스토그램을 사용하는 것입니다.
Layers list 에서 SRTM DEM 레이어를 오른쪽 클릭하십시오.
Properties 를 선택합니다.
Histogram 탭을 선택하십시오. 그래픽을 생성하려면 Compute Histogram 버튼을 클릭해야 할 수도 있습니다. 이미지 안의 값들의 빈도를 나타내는 그래프를 볼 수 있을 것입니다.
다음과 같이 그래프를 이미지로 내보낼 수 있습니다.

Metadata 탭을 선택하면, Properties 박스 안에서 더 상세한 정보를 찾아볼 수 있습니다.
평균값은 332.8 이고, 최대값은 1699 입니다! 하지만 히스토그램에서 이 값들을 찾아볼 수 없습니다. 왜일까요? 평균 이하의 값을 가진 픽셀들이 어마어마한 개수에 비해 너무 적기 때문입니다. 또 약 250 이상인 값들의 빈도를 표시하는 빨간 줄이 보이지 않는 데도 히스토그램이 오른쪽으로 길게 연장되어 있는 이유이기도 합니다.
따라서 히스토그램은 값들의 분포를 보여줄 뿐, 그래프 상에 모든 값을 보여주지 않을 수도 있다는 점을 기억해야 합니다.
(이제 Layer Properties 를 닫아도 됩니다.)
7.4.7. Follow Along: 공간 보간법¶
여러분이 어떤 샘플 포인트 집합으로부터 데이터를 추정하고자 한다고 해봅시다. 예를 들어 이번에 생성한 random_samples 데이터셋에 접근할 수 있는데, 이로부터 해당 지형이 어떻게 생겼는지 감을 잡고자 할 수도 있습니다.
메뉴에서 Raster ‣ Analysis ‣ Grid (Interpolation) 항목을 클릭해서 Grid (Interpolation) 도구를 실행하십시오.
Input file 항목에
random_samples를 선택하십시오.Z Field 체크박스를 체크하고,
srtm_41_19항목을 선택하십시오.Output file 경로를
exercise_data/spatial_statistics/interpolation.tif로 설정합니다.Algorithm 체크박스를 체크하고, Inverse distance to a power 를 선택하십시오.
Power 를
5.0로, Smoothing 을2.0로 설정하십시오. 다른 값은 변경하지 않습니다.Load into canvas when finished 체크박스를 체크한 다음 OK 를 클릭하십시오.
완료되면,
Process completed라고 나타나는 대화 창의 OK 를 클릭하고, 피드백 정보를 보여주는 대화 창의 (나타날 경우) OK 를 클릭한 다음, Grid (Interpolation) 대화 창의 Close 를 클릭합니다.
다음은 원래 데이터셋(왼쪽)과 샘플 포인트로부터 구축한 데이터셋(오른쪽)을 비교한 그림입니다. 사용자가 구축한 데이터셋은 샘플 포인트들의 위치의 랜덤성에 따라 달라 보일 수도 있습니다.

그림에 잘 나타나듯이, 샘플 포인트 100개로는 해당 지형의 자세한 인상을 얻기에 턱없이 부족합니다. 아주 전반적인 감을 잡을 수는 있지만 쉽게 오도할 수도 있습니다. 예를 들어 앞의 그림에서 동쪽에서 서쪽으로 이어지는 높은 산맥이 있다는 사실을 알기란 어렵습니다. 사실 서쪽의 높은 봉우리와 그 옆의 골짜기로 이해하기 쉽죠. 육안으로만 살펴보아도 샘플 데이터셋이 해당 지역의 지형을 표현할 수 없다는 사실은 명백합니다.
7.4.8.  Try Yourself¶
Try Yourself¶
앞에서 설명한 과정대로, 새로운 랜덤 포인트
1000개 집합을 생성하십시오.이 포인트들을 이용해서 원 DEM을 샘플링하십시오.
Grid (Interpolation) 도구를 앞에 설명한 대로 이 새로운 데이터셋에 사용하십시오.
Power 를
5.0로, Smoothing 을2.0로 설정하고 산출물 파일명을interpolation_1000.tif로 설정하십시오.
결과물은 (여러분의 랜덤 포인트 위치에 따라) 다음과 비슷하게 보일 것입니다.
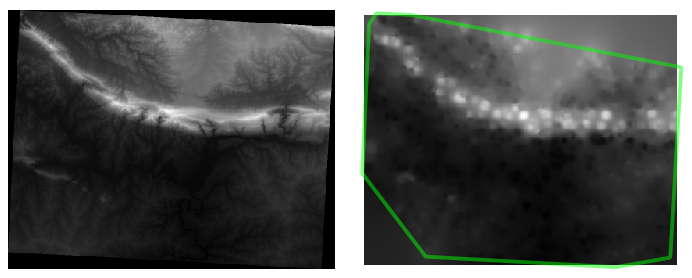
경계선 바깥에서 갑작스럽게 세부 표현이 떨어지는 사실을 설명하기 위해 (랜덤한 샘플 포인트의 범위를 나타내는) roads_hull 레이어의 윤곽선을 보이게 했습니다. 샘플 포인트의 밀도가 훨씬 높기 때문에 지형을 더 잘 표현하고 있습니다.
다음은 샘플 포인트가 10 000 개일 경우 어떻게 보이는지에 대한 예시입니다.
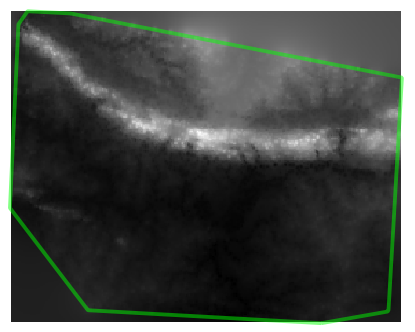
주석
샘플 데이터셋의 용량이 클수록 처리 시간이 늘어나기 때문에, 사용자의 컴퓨터 속도가 빠르지 않다면 샘플 포인트 1만 개로 실습하지 않는 편이 낫습니다.
7.4.9. Follow Along: 그 외의 공간 분석 도구들¶
QGIS 버전 2.0부터, 원래 개별 프로젝트로 시작해서 플러그인으로서 접근할 수 있게 된 SEXTANTE 소프트웨어가 핵심 기능으로 추가되었습니다. QGIS의 새로운 메뉴인 Processing 에서 이 도구를 찾을 수 있습니다. Processing 메뉴를 통해 단일 인터페이스에서 다양한 플러그인 도구에 접근할 수 있게 해주는 공간 분석 도구들의 다채로운 툴박스에 접근할 수 있습니다.
메뉴에서 Processing ‣ Toolbox 항목을 선택해서 이 도구들을 활성화시키십시오. 해당 툴박스는 다음과 같은 모양을 하고 있습니다.

이 툴박스는 QGIS 맵 화면 오른쪽에 붙게 됩니다. 이 도구 목록은 실제 도구들로의 링크라는 점을 주의하십시오. 일부는 SEXTANTE의 자체 알고리듬들이고, 다른 일부는 GRASS, SAGA 또는 Orfeo Toolbox와 같은 외부 응용 프로그램으로 접근하는 링크입니다. 이 외부 응용 프로그램들은 QGIS와 함께 설치되므로 여러분은 그대로 이 도구들을 사용할 수 있습니다. Processing 도구들의 설정을 변경해야 하거나, 또는 예를 들어 외부 응용 프로그램 가운데 하나를 최신 버전으로 업데이트해야 할 경우, Processing ‣ Options and configurations 메뉴에서 설정을 변경할 수 있습니다.
7.4.10. Follow Along: 공간 포인트 패턴 분석¶
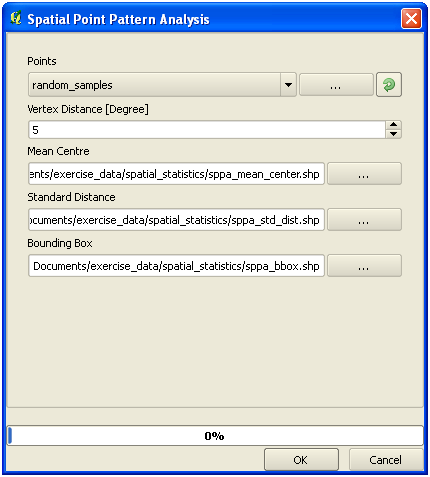
random_samples 데이터셋에서 포인트들의 공간 분포를 간단히 표현하려면, 여러분이 방금 열었던 Processing Toolbox 를 통해 SAGA의 Spatial Point Pattern Analysis 도구를 사용할 수 있습니다.
Processing Toolbox 에서 Spatial Point Pattern Analysis 도구를 찾아보십시오.
해당 도구를 더블클릭하면 대화 창이 열립니다.
7.4.10.1. SAGA 설치¶
주석
사용자 시스템에 SAGA가 설치되어 있지 않다면 플러그인의 대화 창에서 의존성이 누락되었다고 알려줄 것입니다. 그렇지 않다면 이 단계를 건너뛰어도 됩니다.
7.4.10.2. 윈도우 시스템¶
여러분의 강의 자료에 윈도우용 SAGA 설치 파일이 포함돼 있습니다.
프로그램을 실행하고 절차에 따라 사용자의 윈도우 시스템에 SAGA를 설치합니다. 설치 경로를 확인해두십시오!
SAGA 설치를 완료하면, SEXTANTE에 해당 설치 경로를 설정해야 합니다.
메뉴에서 Analysis ‣ SAGA options and configuration 항목을 클릭하십시오.
대화 창이 뜨면, SAGA 항목을 확장해서 SAGA folder 를 찾으십시오. 비어 있을 것입니다.
해당 란에 사용자가 SAGA를 설치한 경로를 입력합니다.
7.4.10.3. 우분투 시스템¶
Software Center 에서 SAGA GIS 를 검색하거나, 터미널에서
sudo apt-get install saga-gis명령어를 입력합니다. (먼저 사용자의 자원에 SAGA 저장소를 추가해야 할 수도 있습니다.)QGIS가 자동적으로 SAGA를 찾을 것입니다. 하지만 한 번에 실행되지 않을 경우 QGIS를 재시작해야 할 수도 있습니다.
7.4.10.4. Mac 시스템¶
Homebrew 사용자는 다음 명령어로 SAGA를 설치할 수 있습니다.
brew install saga-core
Homebrew 사용자가 아니라면 다음 절차를 따르십시오.
http://sourceforge.net/apps/trac/saga-gis/wiki/Compiling%20SAGA%20on%20Mac%20OS%20X
7.4.10.5. 설치 후¶
이제 SAGA를 설치하고 설정했으니, SAGA의 기능을 사용할 수 있게 됐습니다.
7.4.10.6. SAGA 사용¶
SAGA 대화 창을 엽니다.
SAGA는 산출물 3개를 생성하기 때문에 산출물 경로도 3개가 필요합니다.
exercise_data/spatial_statistics/디렉터리 아래에 세 산출물을 저장하도록 설정하십시오. 파일명은 자유롭게 선택하십시오.
산출물은 다음과 같이 보일 것입니다. (이 예제와는 심볼이 다를 수도 있습니다.)

빨간 점은 평균 중앙이고, 큰 원은 평균 중앙 주변으로 포인트들이 얼마나 가까이 분포되어 있는지를 나타내는 표준 거리이며, 사각형은 모든 포인트들을 감싸는 가능한 한 작은 범위 상자(bounding box)입니다.
7.4.11. Follow Along: 최소 거리 분석¶
알고리듬의 산출물이 shapefile이 아니라 데이터셋의 통계 속성을 종합한 테이블일 경우가 종종 있습니다. Minimum Distance Analysis 도구가 그 가운데 하나입니다.
Processing Toolbox 에서 Minimum Distance Analysis 라는 도구를 찾아보십시오.
분석할 벡터 포인트 데이터셋을 설정하는 일 외에는 어떤 입력도 할 필요가 없습니다.
random_points 데이터셋을 선택하십시오.
OK 를 클릭합니다. 완료되면, Layers list 에 DBF 테이블이 나타날 것입니다.
해당 테이블을 선택해서 속성 테이블을 여십시오. 값은 다를 수도 있지만, 이 결과물은 다음 서식으로 되어 있을 것입니다.

7.4.12. In Conclusion¶
QGIS를 사용하면 데이터셋의 속성에 대해 다양한 공간 통계 분석을 할 수 있습니다.
7.4.13. What’s Next?¶
이제 벡터 분석에 대한 내용을 마쳤으니, 래스터에 대해 알아보는 것은 어떨까요? 이것이 다음 모듈의 주제입니다!